Serving Settings
Serving 상세 페이지의 Settings 탭에서 추론 서버, 트래픽, Transformer를 설정합니다.
- Inference Server
- Traffic Management
Auto Scaling은 요청 부하에 따라 Pod 수를 자동으로 늘리거나 줄이는 기능입니다. 트래픽이 불규칙하거나 예측하기 어려운 서비스에 적합합니다. 고정된 수의 Pod를 항상 유지하려면 비활성화하고 Replicas만 조정하세요.
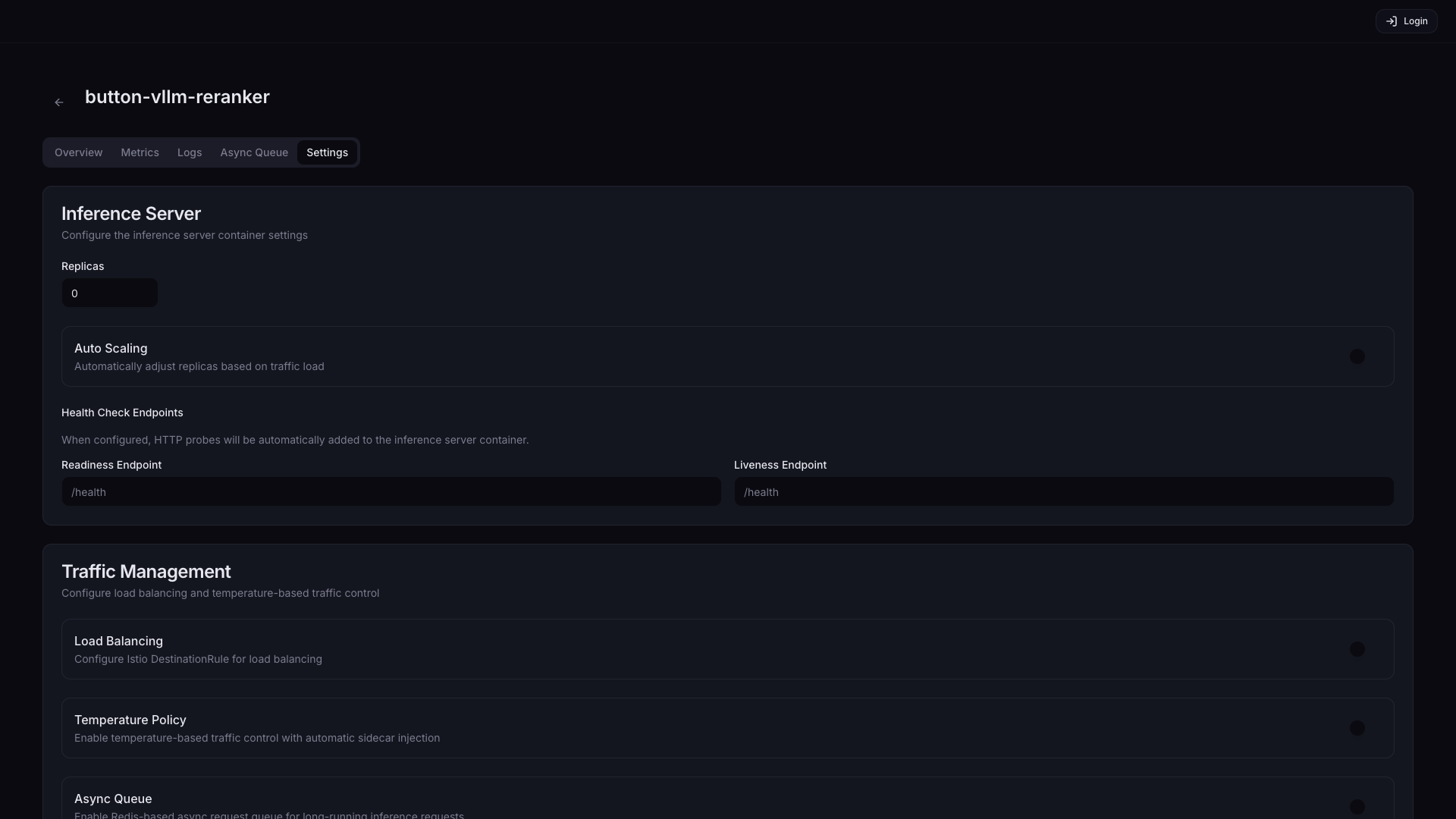
| 설정 | 설명 | 기본값 |
|---|---|---|
| Replicas | 레플리카 수 조정 | 1 |
| Auto Scaling | 트래픽 부하에 따라 Pod 수 자동 조절 | Off |
| Readiness Endpoint | Pod가 트래픽 받을 준비 여부 확인 엔드포인트 (예: /health, /v1/models) | - |
| Liveness Endpoint | Pod 정상 동작 여부 확인. 반복 실패 시 자동 재시작 (예: /health, /healthz) | - |
Auto Scaling 활성화 시 추가 설정:
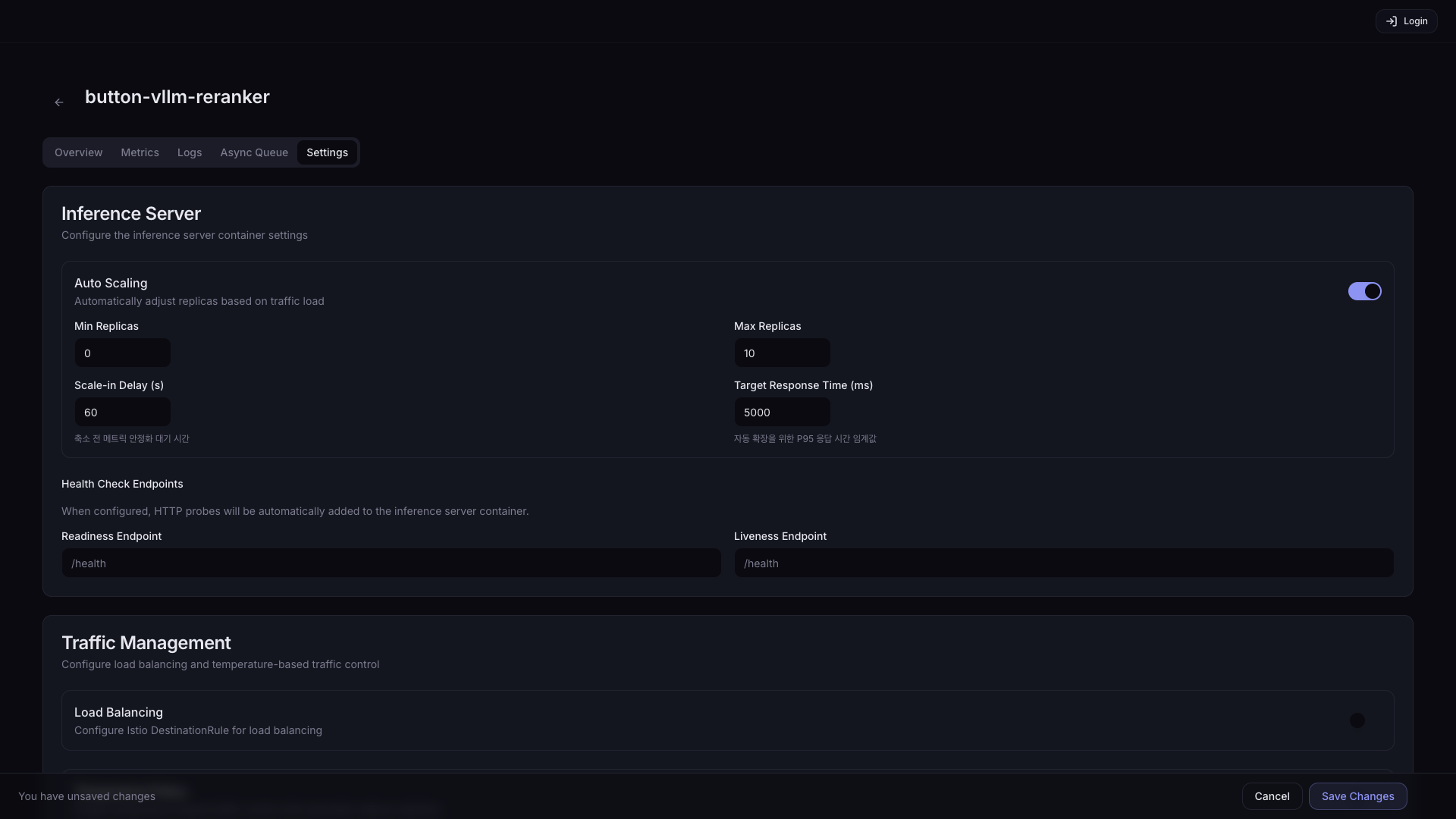
| 설정 | 설명 | 기본값 |
|---|---|---|
| Min Replicas | 항상 유지할 최소 Pod 수. 0으로 설정하면 트래픽이 없을 때 Pod가 완전히 종료되어 리소스를 절약할 수 있지만, 새 요청 시 Pod 기동까지 cold start 지연(수십 초~수 분)이 발생합니다. | 1 |
| Scale-in Delay (s) | 트래픽 감소 후 Pod 축소까지 대기 시간 (flapping 방지) | 60 |
| Max Replicas | 최대 Pod 수 (클러스터 가속기 여유분 고려 필요) | 10 |
| Target Response Time (ms) | 자동 확장 기준 P95 응답 시간 목표값. 초과 시 Pod 증가 | 5000 |
Traffic Management는 여러 Pod로의 요청 분산 방식, 온도 기반 트래픽 보호, 비동기 처리를 제어하는 기능 모음입니다. 단일 Pod로 운영 중이면 Load Balancing과 Temperature Policy는 비활성화 상태로 두어도 무방합니다. Async Queue는 응답 대기 없이 요청을 제출하고 나중에 결과를 조회하는 비동기 워크플로우에 사용합니다.
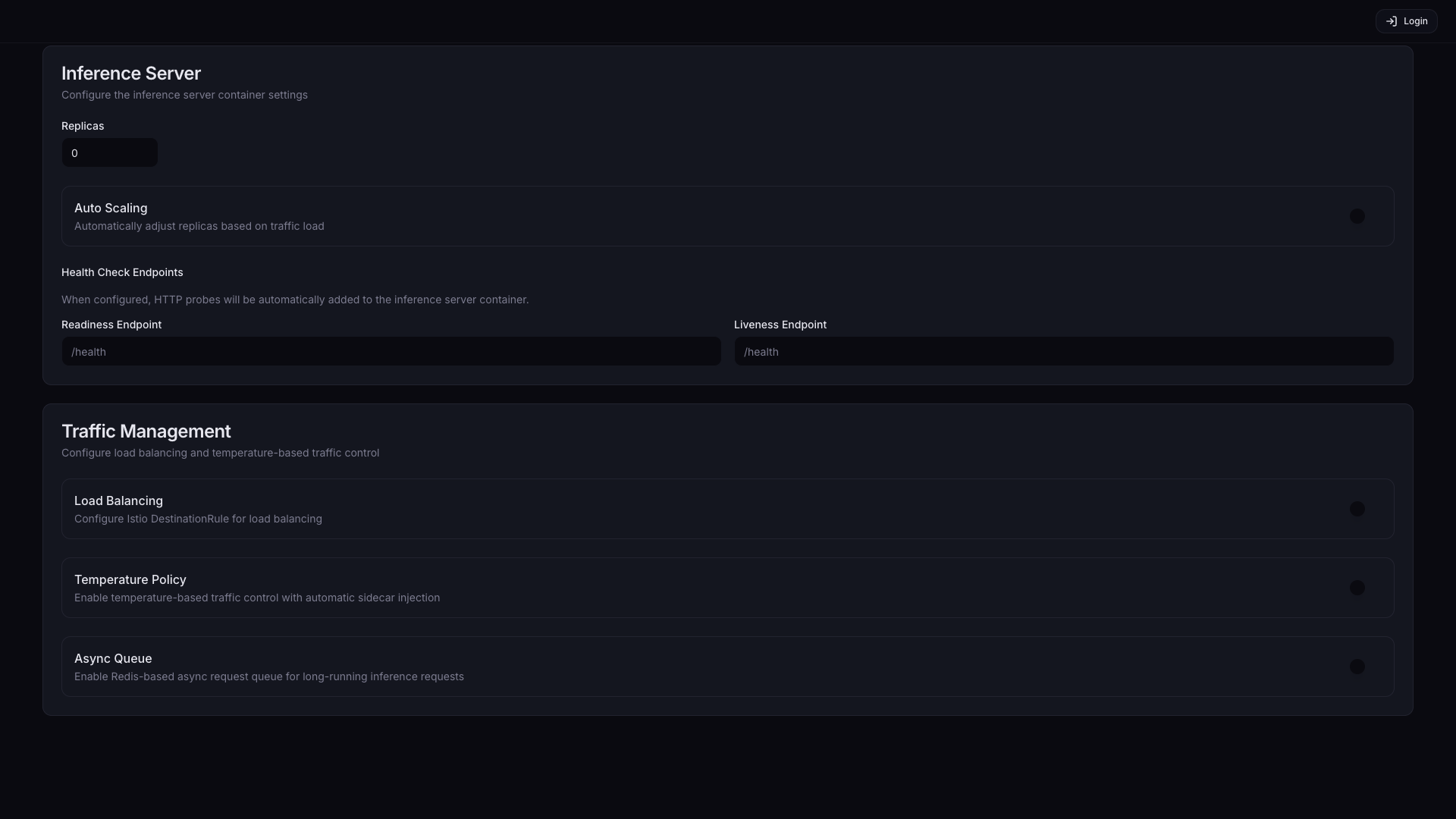
| 기능 | 설명 | 기본값 |
|---|---|---|
| Load Balancing | 여러 Pod로 요청 분산. Replicas가 2 이상인 경우 활성화를 권장합니다. | Off |
| Temperature Policy | GPU/NPU 온도 임계값 초과 시 해당 Pod 트래픽 자동 차단, 회복 시 재개. 장시간 고부하 추론 시 하드웨어 보호를 위해 활성화를 권장합니다. | Off |
| Async Queue | Redis 기반 비동기 요청 큐 활성화. 클라이언트가 요청 제출 후 즉각 응답을 기다리지 않아도 되는 배치 추론 또는 장시간 소요 작업에 적합합니다. | Off |
Load Balancing 활성화 시 Policy 드롭다운이 나타납니다:
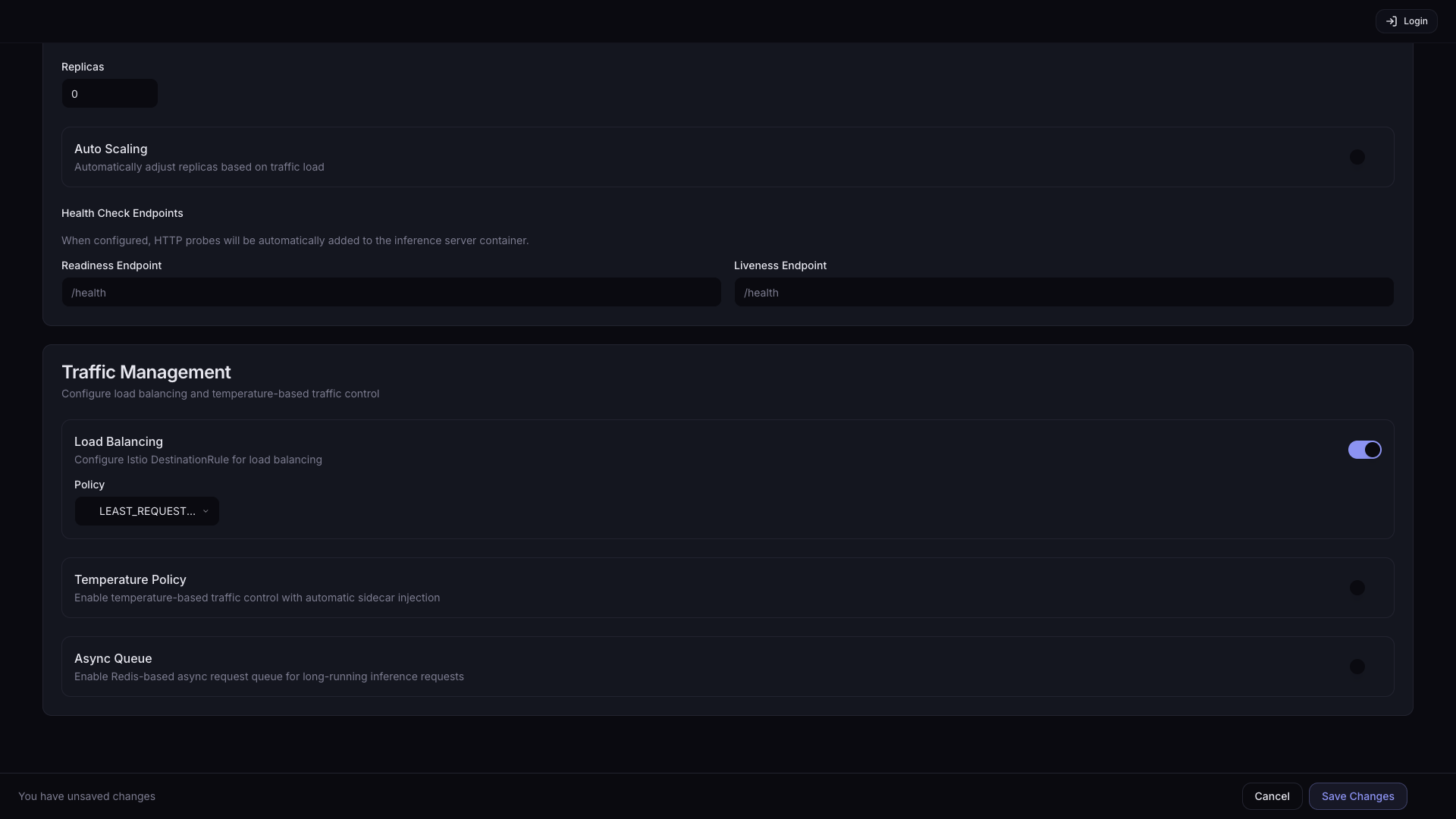
| 옵션 | 설명 |
|---|---|
| LEAST_REQUEST (기본값) | 활성 요청 수가 가장 적은 Pod로 라우팅 |
| ROUND_ROBIN | Pod들을 순서대로 돌아가며 라우팅 |
| RANDOM | 무작위로 Pod를 선택하여 라우팅 |
Temperature Policy 활성화 시 임계값 설정이 나타납니다:
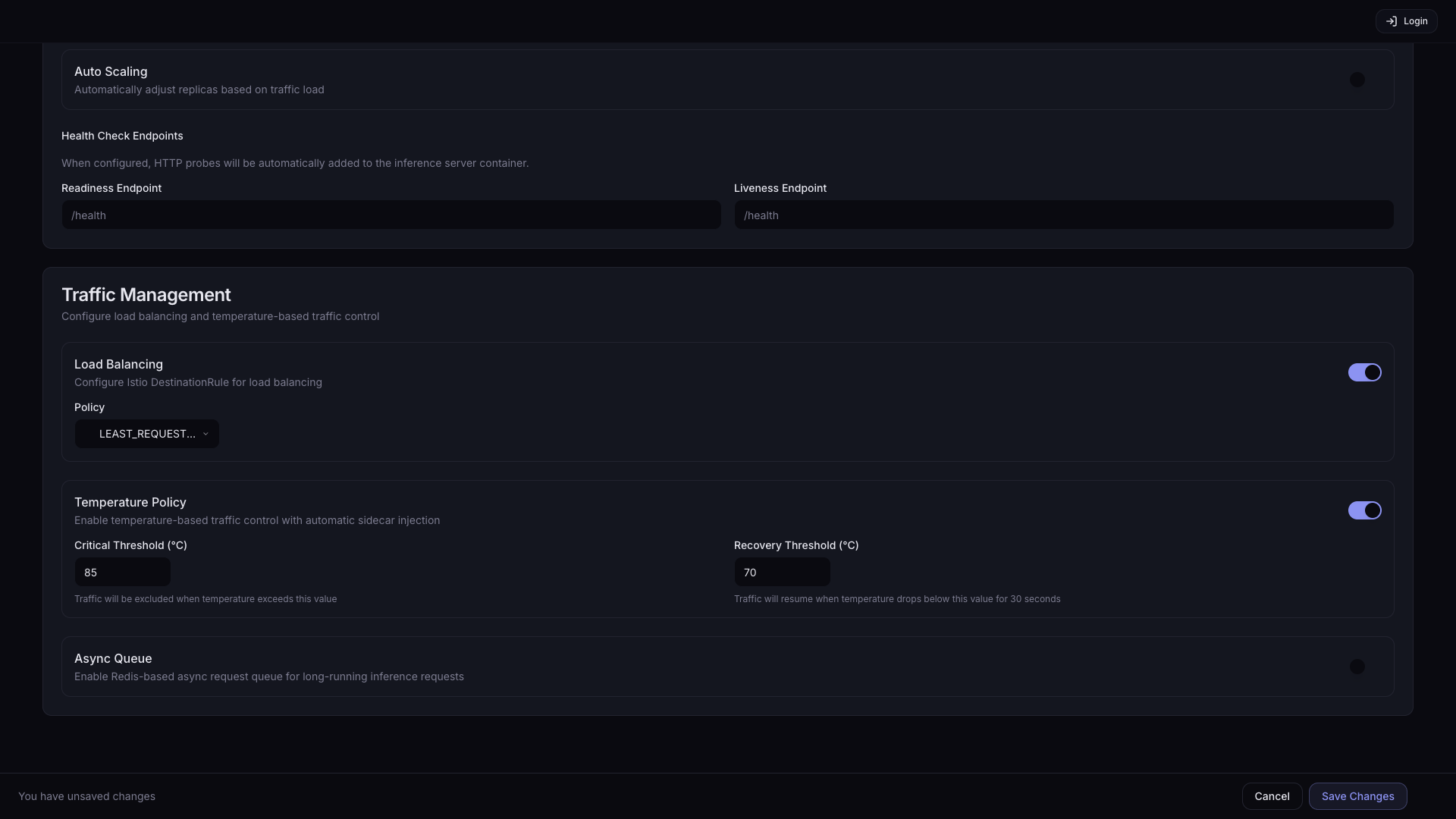
| 설정 | 설명 | 기본값 |
|---|---|---|
| Critical Threshold (°C) | 트래픽 차단 온도 기준 | 85 |
| Recovery Threshold (°C) | 트래픽 재개 온도 기준 | 70 |