Playground
이 페이지에서는 배포된 모델에 직접 메시지를 보내고, 여러 Serving를 나란히 비교하며 프롬프트와 파라미터를 실험할 수 있습니다. 서비스 배포 전 응답 품질 검증, 모델 간 비교, 파라미터 튜닝에 활용합니다.
좌측 사이드바의 Playground 항목을 클릭하면 Playground 페이지로 이동합니다. 페이지 상단의 Device / Model 탭으로 상단 상태 바 메트릭 종류를 전환할 수 있습니다. 두 탭 모두 동일한 채팅 UI를 제공하며, 상태 바에 표시되는 지표만 달라집니다.
| 탭 | 상태 바 지표 |
|---|---|
| Device | 하드웨어 메트릭 — CPU / 온도 / 전력 / 메모리 |
| Model | 추론 성능 메트릭 — TTFT / ITL / Output TPS / 전성비(tok/s/W) |
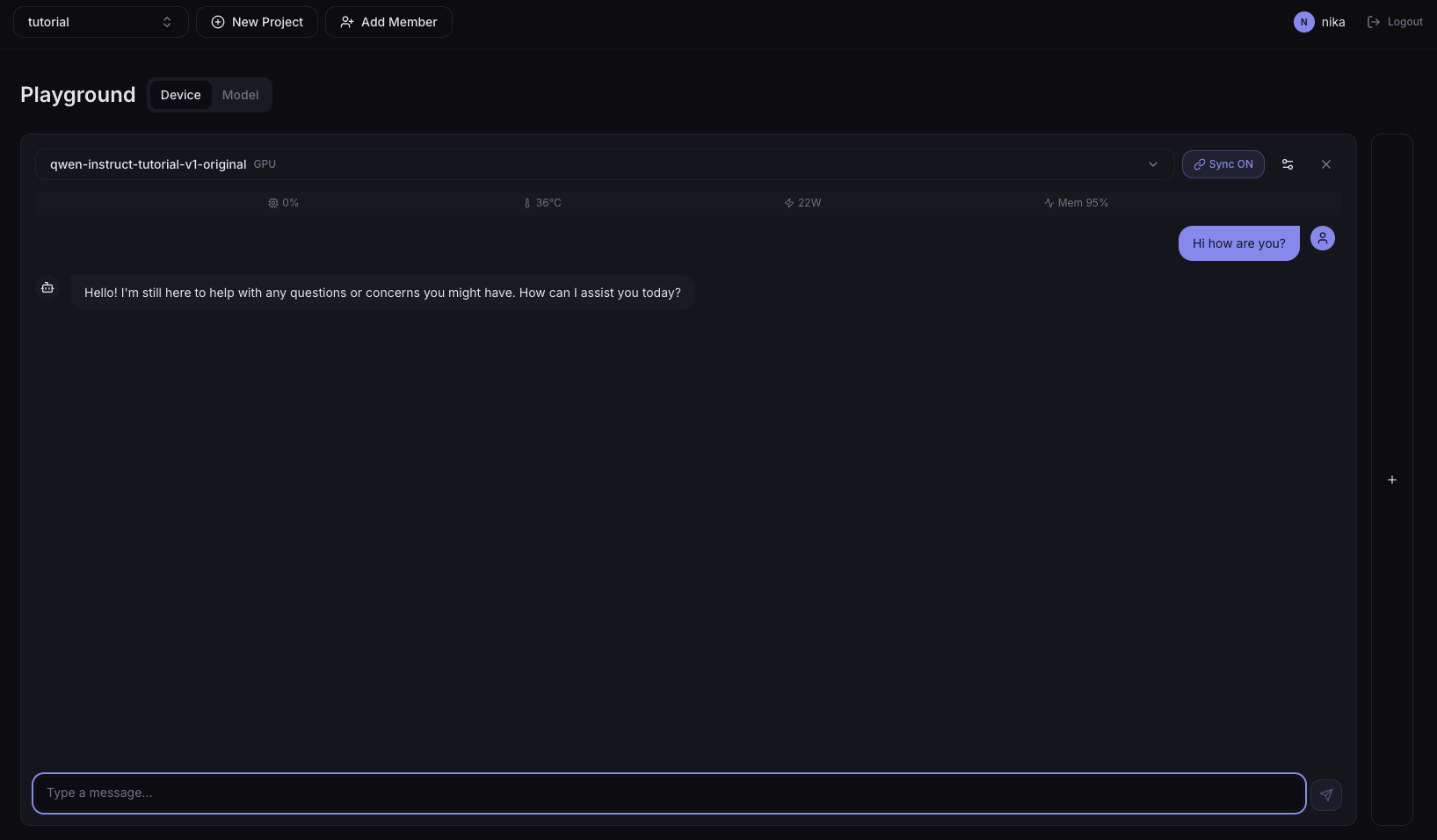
아래는 GPU 배포를 선택한 Device 탭의 예시입니다. 채팅 전송 후 상단 상태 바에 사용률·온도·전력·메모리가 실시간으로 갱신되며, 상태 바를 클릭하면 최근 5분 시계열 차트를 확인할 수 있습니다.
Device 탭
Device 탭에서는 기존 채팅 UI와 하드웨어 메트릭을 함께 확인할 수 있습니다.
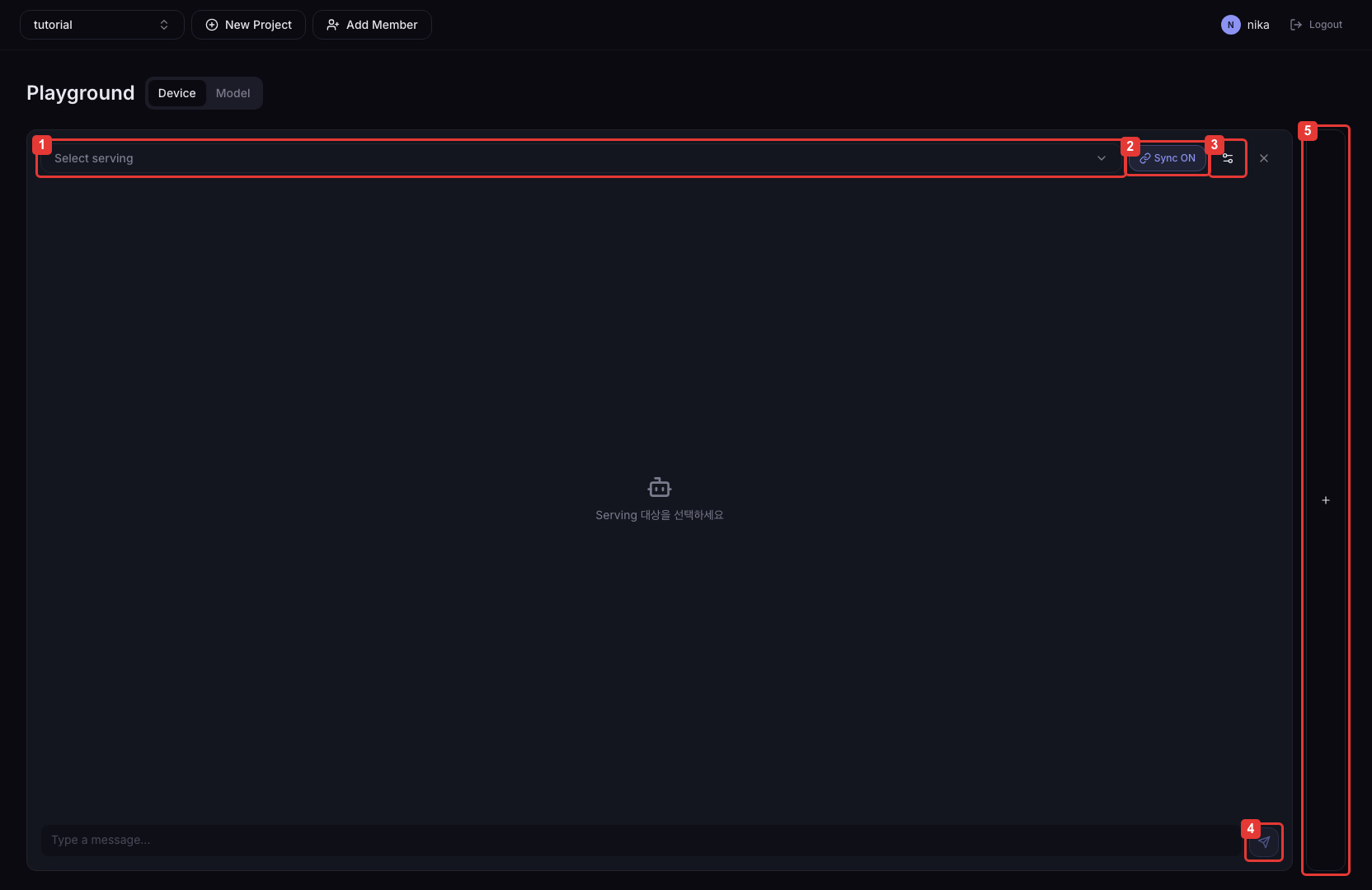
| 번호 | 설명 |
|---|---|
| ① | 비교할 Serving 선택 드롭다운. OpenAI 호환 API를 지원하는 Serving만 표시됩니다 |
| ② | 활성화 시 모든 패널에 동일한 메시지를 동시에 전송하여 응답을 비교합니다 |
| ③ | System Prompt, Temperature, Max Tokens, Top P 등 추론 파라미터를 설정합니다 |
| ④ | 현재 패널의 메시지를 전송합니다. 응답은 SSE 스트리밍으로 수신됩니다 |
| ⑤ | 비교 패널을 추가합니다. 최대 4개까지 나란히 배치할 수 있습니다 |
Model 탭 — 추론 성능 메트릭
Model 탭은 Device 탭과 동일한 채팅 UI를 제공하며, 상단 상태 바가 하드웨어 메트릭 대신 LLM 추론 성능 지표로 교체됩니다. 채팅으로 모델에 요청을 보내면서 TTFT·TPS 등 서비스 응답 품질 지표를 실시간으로 확인할 수 있어, GPU와 NPU 배포 비교나 파라미터 튜닝 결과를 수치로 모니터링할 때 활용합니다.
PanelInferenceBar 상태 바에 다음 4개 지표가 실시간 표시됩니다.
| 지표 | 설명 |
|---|---|
| TTFT(p50) | 첫 번째 토큰이 생성되기까지의 중앙값 시간 (Time To First Token, 밀리초) |
| ITL(p50) | 토큰 간 생성 간격 중앙값 (Inter-token Latency, 밀리초) |
| Output TPS | 초당 출력 토큰 수 (Tokens Per Second) |
| Tokens/sec/Watt | 소비 전력 1W당 생성 토큰 수 (전성비) |
PanelInferenceBar를 클릭하면 최근 5분간의 시계열 팝오버가 표시됩니다. TTFT, ITL, Output TPS, tok/s/W 4개 라인 차트로 추세를 확인할 수 있습니다.
- GPU(NVIDIA) 배포: vLLM 메트릭(
vllm:*) + DCGM 전력 메트릭 사용 - RNGD(Furiosa) 배포: furiosa-llm 메트릭(
furiosa_llm_*) +furiosa_npu_hw_power사용
메트릭 소스는 Serving에 할당된 가속기 유형에 따라 자동으로 분기됩니다.
Serving 선택 및 Sync
각 패널 상단의 ① Select Serving 드롭다운에서 비교할 Serving를 선택합니다. OpenAI 호환 API(/v1/chat/completions)를 지원하는 Serving만 목록에 표시됩니다.
② Sync 버튼을 활성화하면 모든 패널에 동일한 메시지를 동시에 전송하여 응답을 한 번에 비교할 수 있습니다.
파라미터 설정
③ Settings 버튼을 클릭하면 파라미터를 조정하거나 대화를 초기화할 수 있습니다.
| 파라미터 | 설명 | 범위 | 기본값 |
|---|---|---|---|
| System Prompt | 모델의 역할과 동작 방식을 정의하는 사전 지시문 | — | — |
| Temperature | 응답의 무작위성 조절. 높을수록 다양하고 창의적인 응답, 낮을수록 일관된 응답 | 0 – 2 | 0.7 |
| Max Tokens | 생성할 최대 토큰 수 | 1 – 4096 | 2048 |
| Top P | 상위 확률 토큰만 샘플링. Temperature와 함께 다양성 조절 | 0 – 1 | 1.0 |
| Presence Penalty | 이미 언급된 주제의 반복을 줄여 새로운 주제 유도 | 0 – 2 | 0.0 |
| Frequency Penalty | 같은 단어·구문의 반복 사용을 줄여 표현 다양화 | 0 – 2 | 0.0 |
일반적으로 Temperature와 Top P 중 하나만 조정합니다. 둘 다 기본값이 아닌 경우 예측하기 어려운 응답이 나올 수 있습니다.