Lab에서 RAG 챗봇 구성하기
Lab에서 문서를 볼륨에 업로드하고, 임베딩 서버와 Vector DB로 인덱싱한 뒤, RAG 백엔드(FastAPI) 와 Streamlit UI를 각각 이미지로 빌드해 NuFi Serving으로 배포합니다. 최종 동작은 외부 노출된 Streamlit UI에서 확인합니다.
NuFi Serving이 외부로 노출하는 API는 OpenAI 호환 스펙만 허용됩니다. 이 튜토리얼의 RAG 백엔드는 출처·점수 등을 자유롭게 담는 자체 스펙(POST /query)으로 작성하기 때문에 Playground로 직접 띄울 수 없습니다. 대신 RAG 백엔드를 내부 호출 전용으로 두고, Streamlit UI Serving을 외부 노출 지점으로 사용합니다.
구성
Volume: tutorial-volume
└─ /data/docs # Lab에서 업로드한 문서
Lab (tutorial-volume을 /data에 마운트)
└─ 문서 청킹, 임베딩, Vector DB 적재
Serving: tutorial-embedding
└─ 문서와 질문을 벡터로 변환 (OpenAI 호환 /v1/embeddings)
Vector DB
└─ collection: nufi-rag-tutorial
Serving: tutorial-llm
└─ vLLM 기반 LLM API (OpenAI 호환 /v1/chat/completions)
Serving: tutorial-rag-backend ← 내부 호출 전용
└─ POST /query
└─ Vector DB 검색 → 프롬프트 구성 → LLM 호출 → 답변 + 출처 반환
Serving: tutorial-rag-ui ← 외부 노출 지점
└─ Streamlit
└─ tutorial-rag-backend 호출 → 답변 + 출처 렌더링
사전 조건
- Volumes를 참조하여 이 튜토리얼용 Volume
tutorial-volume생성 - Lab을 참조하여 GPU 또는 NPU를 이용해 Lab 생성 (위 Volume을
/data에 마운트) - E2E 모델 서빙 시나리오 중 하나를 따라 vLLM 기반 LLM Serving 배포. 본문에서는 이 LLM Serving을
tutorial-llm으로 표기합니다. 실제 Serving 이름은 Quick Deploy 시<model-name>-<version>-<artifact>형식으로 자동 생성되며(예:qwen-instruct-tutorial-v1-original), Development > Serving 목록에서 그대로 확인할 수 있습니다. 환경변수의LLM_BASE_URL호스트 부분은 본인 환경의 실제 이름으로 치환해 사용합니다. - 관리자에게 받은 Vector DB 접속 정보 (Vector DB 배포 페이지에서도 접속 정보를 확인할 수 있습니다)
- 이미지 빌드 환경 (Docker/Podman) 및 푸시 가능한 레지스트리
1. Lab에 문서 업로드
Volume 상세 페이지에서 Files 탭을 누르면 Upload 버튼이 있습니다. 이 버튼을 이용해 RAG에 사용할 문서를 tutorial-volume에 업로드합니다.
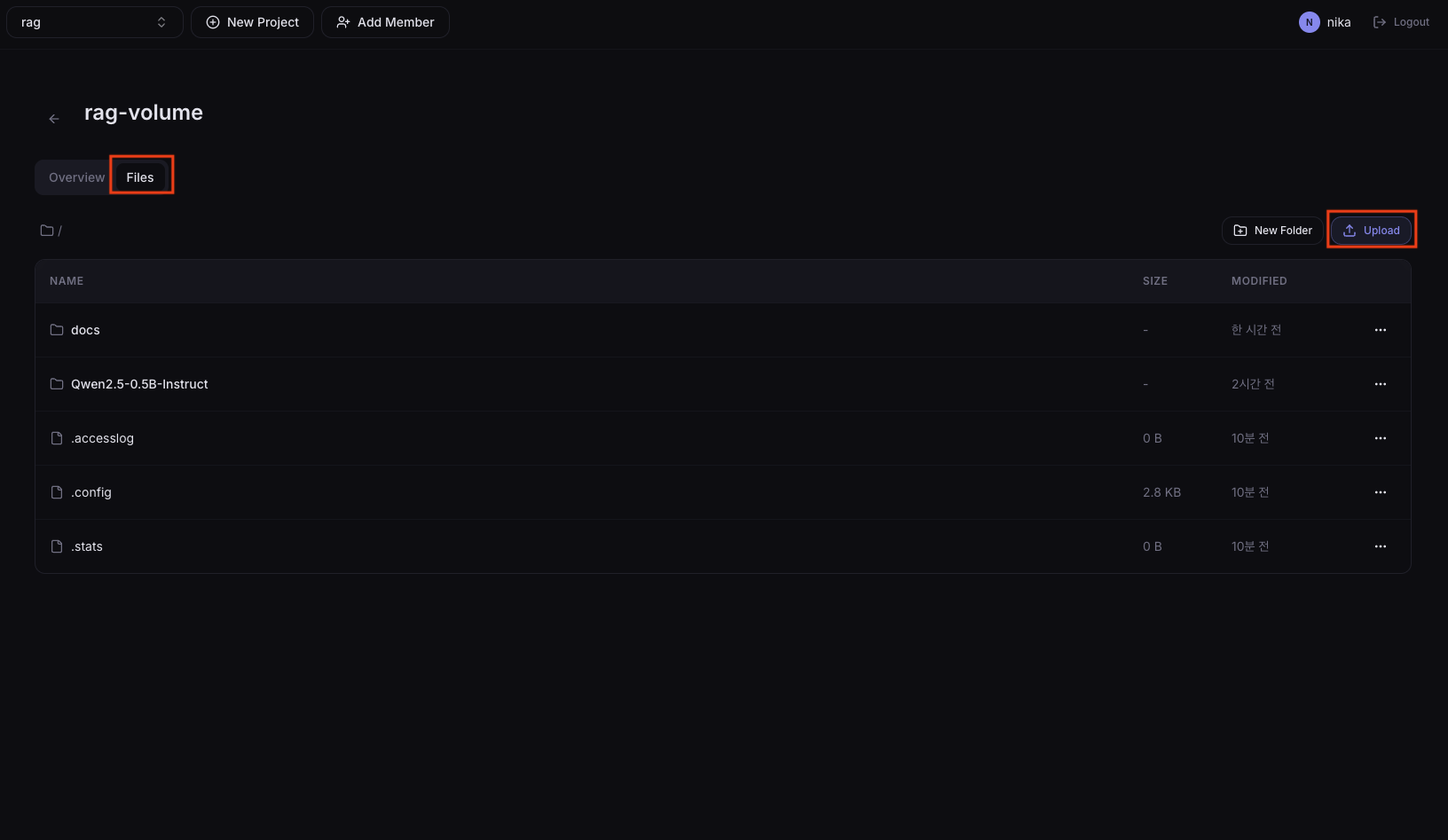
현재 튜토리얼의 하단 인덱싱 코드는 PDF/DOCX 같은 문서 파싱을 지원하지 않습니다. 텍스트 파일(.md, .txt 등)만 사용해 주세요.
2. Embedding Serving 배포
Development > Serving > Create로 이동하여 임베딩 서버를 배포합니다.
Step 1 — 기본 정보
| 필드 | 입력값 |
|---|---|
| Service Name | tutorial-embedding |
| Description | RAG embedding server |
| Service Template | Custom |
Step 2 — 상세 설정
| 필드 | 입력값 |
|---|---|
| Image | ghcr.io/huggingface/text-embeddings-inference:cpu-1.7 |
| CPU | 2 |
| Memory | 16 |
| Accelerator Type | None |
| Replicas | 1 |
| Inference Port | 80 |
Command / Args
--model-id
intfloat/multilingual-e5-base
배포 후 Development > Serving 목록에서 tutorial-embedding이 Running 상태인지 확인합니다.
다른 Lab 또는 Serving에서 호출할 때는 NuFi가 만든 Service의 80번 포트를 사용합니다.
http://tutorial-embedding.<project-namespace>.svc:80
이 URL은 아래 3. Lab에서 Vector DB에 문서 적재 단계의 인덱싱 스크립트에서 OPENAI_API_BASE(EMBEDDING_BASE_URL) 값으로 사용됩니다.
3. Lab에서 Vector DB에 문서 적재
Vector DB 접속 정보(URL, API Key, Collection 등)는 관리자에게 받습니다. 현재 튜토리얼은 Qdrant를 사용하는 것을 기준으로 진행합니다.
Lab 터미널에서 필요한 패키지를 설치합니다.
pip install langchain langchain-community langchain-openai langchain-qdrant qdrant-client
아래 스크립트를 사용해 LangChain으로 문서 로딩, 청킹, 임베딩, Vector DB 적재까지 수행합니다. 실제 질문 응답은 이후 배포할 RAG 백엔드 Serving이 처리합니다.
PROJECT_NAMESPACE, VECTOR_DB_URL은 환경에 맞게 바꿉니다. Vector DB가 API key를 사용한다면 QdrantClient에 api_key="..."를 추가합니다.
from pathlib import Path
from langchain_community.document_loaders import DirectoryLoader, TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_qdrant import QdrantVectorStore
from langchain_text_splitters import RecursiveCharacterTextSplitter
from qdrant_client import QdrantClient
from qdrant_client.models import Distance, VectorParams
PROJECT_NAMESPACE = "<project-namespace>" # 현재 프로젝트의 네임스페이스로 변경 (상단 헤더의 프로젝트 네임스페이스 영역에서 확인)
DOCS_DIR = Path("/data/docs")
EMBEDDING_BASE_URL = f"http://tutorial-embedding.{PROJECT_NAMESPACE}.svc:80/v1"
EMBEDDING_MODEL = "intfloat/multilingual-e5-base"
VECTOR_DB_URL = "http://qdrant.vector-db.svc:6333"
COLLECTION = "nufi-rag-tutorial"
VECTOR_SIZE = 768
qdrant = QdrantClient(url=VECTOR_DB_URL)
if not qdrant.collection_exists(COLLECTION):
qdrant.create_collection(
collection_name=COLLECTION,
vectors_config=VectorParams(size=VECTOR_SIZE, distance=Distance.COSINE),
)
loader = DirectoryLoader(
str(DOCS_DIR),
glob="**/*",
loader_cls=TextLoader,
loader_kwargs={"encoding": "utf-8"},
show_progress=True,
)
docs = loader.load()
chunks = RecursiveCharacterTextSplitter(
chunk_size=400,
chunk_overlap=80,
).split_documents(docs)
embeddings = OpenAIEmbeddings(
model=EMBEDDING_MODEL,
base_url=EMBEDDING_BASE_URL,
api_key="unused",
)
vector_store = QdrantVectorStore(
client=qdrant,
collection_name=COLLECTION,
embedding=embeddings,
)
vector_store.add_documents(chunks)
print(f"indexed {len(chunks)} chunks into {COLLECTION}")
PROJECT_NAMESPACE 값은 화면 상단 헤더의 프로젝트 네임스페이스 영역에서 확인할 수 있습니다.
정상 실행되면 indexed ... chunks into nufi-rag-tutorial 메시지가 출력됩니다.
4. RAG 백엔드 및 UI 코드 살펴보기 (선택)
RAG 백엔드는 사용자의 질문을 받아 Vector DB를 검색하고, 검색 결과를 프롬프트에 넣어 vLLM Serving을 호출하는 FastAPI 서버입니다. 클러스터 내부 호출 전용이므로 OpenAI 스펙을 따르지 않고 자체 스펙으로 설계합니다.
Streamlit UI는 RAG 백엔드를 호출해 답변과 출처를 렌더링합니다. RAG 백엔드가 외부에 노출되지 않으므로 사용자 접점 역할을 합니다.
이번 튜토리얼에서는 이미 빌드된 이미지를 제공합니다. 직접 빌드 없이 다음 단계로 진행할 수 있습니다.
registry.dudaji.com/nufi/tutorial-rag-backend:0.1.0
registry.dudaji.com/nufi/tutorial-rag-ui:0.1.0
API 스펙
POST /query- Request:
{ "question": str, "top_k": int(optional, default 4) } - Response:
{"answer": "...","sources": [{ "title": "company-guide.md", "score": 0.82, "snippet": "...", "uri": "/data/docs/company-guide.md" }],"latency_ms": 1234}
- Request:
GET /healthz— 상태 확인용
실제 이미지의 코드를 확인하고 싶거나 자사 환경에서 직접 빌드해 테스트해보고 싶다면 아래를 펼쳐서 확인하세요.
🐍 RAG 백엔드 (FastAPI) 코드 전체
디렉터리 구성
/data/backend/
├─ app.py
├─ requirements.txt
└─ Dockerfile
app.py
import os
import time
from typing import List
from fastapi import FastAPI
from pydantic import BaseModel
from openai import OpenAI
from qdrant_client import QdrantClient
LLM_BASE_URL = os.environ["LLM_BASE_URL"]
LLM_MODEL = os.environ["LLM_MODEL"]
EMBEDDING_BASE_URL = os.environ["EMBEDDING_BASE_URL"]
EMBEDDING_MODEL = os.environ["EMBEDDING_MODEL"]
VECTOR_DB_URL = os.environ["VECTOR_DB_URL"]
VECTOR_DB_API_KEY = os.environ.get("VECTOR_DB_API_KEY", "")
COLLECTION = os.environ["VECTOR_COLLECTION"]
DEFAULT_TOP_K = int(os.environ.get("TOP_K", "4"))
llm = OpenAI(base_url=LLM_BASE_URL, api_key="unused")
embedder = OpenAI(base_url=EMBEDDING_BASE_URL, api_key="unused")
qdrant = QdrantClient(url=VECTOR_DB_URL, api_key=VECTOR_DB_API_KEY or None)
SYSTEM_PROMPT = """당신은 사내 문서를 근거로 답변하는 어시스턴트입니다.
주어진 문서 내용만 사용해 답하고, 근거가 없으면 '문서에서 찾을 수 없습니다.'라고 답하세요."""
class QueryRequest(BaseModel):
question: str
top_k: int | None = None
class Source(BaseModel):
title: str
score: float
snippet: str
uri: str | None = None
class QueryResponse(BaseModel):
answer: str
sources: List[Source]
latency_ms: int
app = FastAPI()
@app.get("/healthz")
def healthz():
return {"ok": True}
@app.post("/query", response_model=QueryResponse)
def query(req: QueryRequest):
started = time.time()
top_k = req.top_k or DEFAULT_TOP_K
emb = embedder.embeddings.create(model=EMBEDDING_MODEL, input=req.question)
qvec = emb.data[0].embedding
hits = qdrant.search(
collection_name=COLLECTION,
query_vector=qvec,
limit=top_k,
with_payload=True,
)
sources: List[Source] = []
context_blocks: List[str] = []
for h in hits:
payload = h.payload or {}
text = payload.get("page_content", "")
meta = payload.get("metadata", {}) or {}
title = meta.get("source", "unknown")
sources.append(
Source(
title=str(title).split("/")[-1],
score=float(h.score),
snippet=text[:240],
uri=str(title),
)
)
context_blocks.append(f"[{title}]\n{text}")
context = "\n\n---\n\n".join(context_blocks) if context_blocks else "(검색 결과 없음)"
user_prompt = f"문서:\n{context}\n\n질문: {req.question}"
chat = llm.chat.completions.create(
model=LLM_MODEL,
messages=[
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": user_prompt},
],
temperature=0.2,
)
answer = chat.choices[0].message.content or ""
latency_ms = int((time.time() - started) * 1000)
return QueryResponse(answer=answer, sources=sources, latency_ms=latency_ms)
requirements.txt
fastapi==0.115.0
uvicorn[standard]==0.30.6
openai==1.51.0
httpx==0.27.2
qdrant-client==1.11.3
pydantic==2.9.2
Dockerfile
FROM python:3.11-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY app.py .
EXPOSE 8000
CMD ["uvicorn", "app:app", "--host", "0.0.0.0", "--port", "8000"]
직접 빌드 및 푸시
cd /data/backend
docker build -t <registry>/tutorial-rag-backend:0.1.0 .
docker push <registry>/tutorial-rag-backend:0.1.0
🐍 Streamlit UI 코드 전체
디렉터리 구성
/data/ui/
├─ app.py
├─ requirements.txt
└─ Dockerfile
app.py
import os
import requests
import streamlit as st
BACKEND_URL = os.environ["BACKEND_URL"] # 예: http://tutorial-rag-backend.<ns>.svc:80
st.set_page_config(page_title="NuFi RAG 챗봇", page_icon="📚")
st.title("📚 NuFi RAG 챗봇")
if "history" not in st.session_state:
st.session_state.history = []
for turn in st.session_state.history:
with st.chat_message(turn["role"]):
st.markdown(turn["content"])
if turn["role"] == "assistant" and turn.get("sources"):
with st.expander("출처"):
for s in turn["sources"]:
st.markdown(f"**{s['title']}** (score: {s['score']:.3f})")
st.caption(s["snippet"])
question = st.chat_input("문서에 대해 질문해보세요")
if question:
st.session_state.history.append({"role": "user", "content": question})
with st.chat_message("user"):
st.markdown(question)
with st.chat_message("assistant"):
with st.spinner("검색 및 응답 생성 중..."):
resp = requests.post(
f"{BACKEND_URL}/query",
json={"question": question},
timeout=120,
)
resp.raise_for_status()
data = resp.json()
st.markdown(data["answer"])
if data.get("sources"):
with st.expander("출처"):
for s in data["sources"]:
st.markdown(f"**{s['title']}** (score: {s['score']:.3f})")
st.caption(s["snippet"])
st.session_state.history.append({
"role": "assistant",
"content": data["answer"],
"sources": data.get("sources", []),
})
requirements.txt
streamlit==1.39.0
requests==2.32.3
Dockerfile
FROM python:3.11-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY app.py .
EXPOSE 8501
CMD ["streamlit", "run", "app.py", \
"--server.port=8501", \
"--server.address=0.0.0.0", \
"--server.enableCORS=false", \
"--server.enableXsrfProtection=false", \
"--server.enableWebsocketCompression=false", \
"--browser.gatherUsageStats=false"]
직접 빌드 및 푸시
cd /data/ui
docker build -t <registry>/tutorial-rag-ui:0.1.0 .
docker push <registry>/tutorial-rag-ui:0.1.0
5. RAG 백엔드 Serving 배포
Development > Serving > Create로 이동합니다.
Step 1 — 기본 정보
| 필드 | 입력값 |
|---|---|
| Service Name | tutorial-rag-backend |
| Description | RAG backend (internal) |
| Service Template | Custom |
Step 2 — 상세 설정
| 필드 | 입력값 |
|---|---|
| Image | registry.dudaji.com/nufi/tutorial-rag-backend:0.1.0 |
| CPU | 1 |
| Memory | 2 |
| Accelerator Type | None |
| Replicas | 1 |
| Inference Port | 8000 |
Environment Variables
LLM_BASE_URL=http://qwen-instruct-tutorial-v1-original.rag.svc:80/v1
LLM_MODEL=/mnt/rag-volume/Qwen2.5-0.5B-Instruct
EMBEDDING_BASE_URL=http://tutorial-embedding.rag.svc:80/v1
EMBEDDING_MODEL=intfloat/multilingual-e5-base
VECTOR_DB_URL=http://qdrant.vector-db.svc:6333
VECTOR_COLLECTION=nufi-rag-tutorial
TOP_K=4
LLM_BASE_URL—http://<llm-service-name>.<project-namespace>.svc:80/v1형식. 사용 중인 LLM Serving의 내부 호출 URL.<llm-service-name>은 LLM Serving 이름,<project-namespace>는 현재 프로젝트 네임스페이스로 치환합니다.LLM_MODEL— vLLM 실행 시--model에 넘긴 모델 ID. Serving 상세의 Command/Args에서--model뒤의 값을 그대로 복사합니다 (--served-model-name을 사용하지 않은 경우).EMBEDDING_BASE_URL—http://tutorial-embedding.<project-namespace>.svc:80/v1형식. 2단계에서 배포한 embedding Serving의 내부 호출 URL.<project-namespace>는 현재 프로젝트 네임스페이스로 치환합니다.EMBEDDING_MODEL— embedding Serving에 사용한 모델 ID.VECTOR_DB_URL— Vector DB 접속 URL. 다른 네임스페이스/포트라면 그에 맞춰 변경합니다. API key가 필요하면VECTOR_DB_API_KEY항목을 추가합니다.VECTOR_COLLECTION— 3단계 인덱싱 스크립트에서 만든 collection 이름과 동일해야 합니다.TOP_K— 검색 시 상위 몇 개의 chunk를 가져올지.
배포 후 tutorial-rag-backend가 Running 상태가 될 때까지 기다립니다. 외부 접속 URL은 사용하지 않으며, 같은 네임스페이스 내부에서만 호출합니다.
6. Streamlit UI Serving 배포
Development > Serving > Create로 이동합니다.
Step 1 — 기본 정보
| 필드 | 입력값 |
|---|---|
| Service Name | tutorial-rag-ui |
| Description | RAG chatbot UI |
| Service Template | Custom |
Step 2 — 상세 설정
| 필드 | 입력값 |
|---|---|
| Image | registry.dudaji.com/nufi/tutorial-rag-ui:0.1.0 |
| CPU | 1 |
| Memory | 2 |
| Accelerator Type | None |
| Replicas | 1 |
| Inference Port | 8501 |
Environment Variables
BACKEND_URL=http://tutorial-rag-backend.rag.svc:80
BACKEND_URL—http://tutorial-rag-backend.<project-namespace>.svc:80형식. 5단계에서 배포한 RAG 백엔드 Serving의 내부 호출 URL.<project-namespace>는 백엔드와 같은 프로젝트 네임스페이스로 치환합니다.
배포 후 Running 상태가 되면 Serving 상세 화면에서 Connect URL을 확인합니다.
7. RAG 응답 확인
Serving 목록에서 tutorial-rag-ui Serving을 찾아 Connect 버튼을 누릅니다.
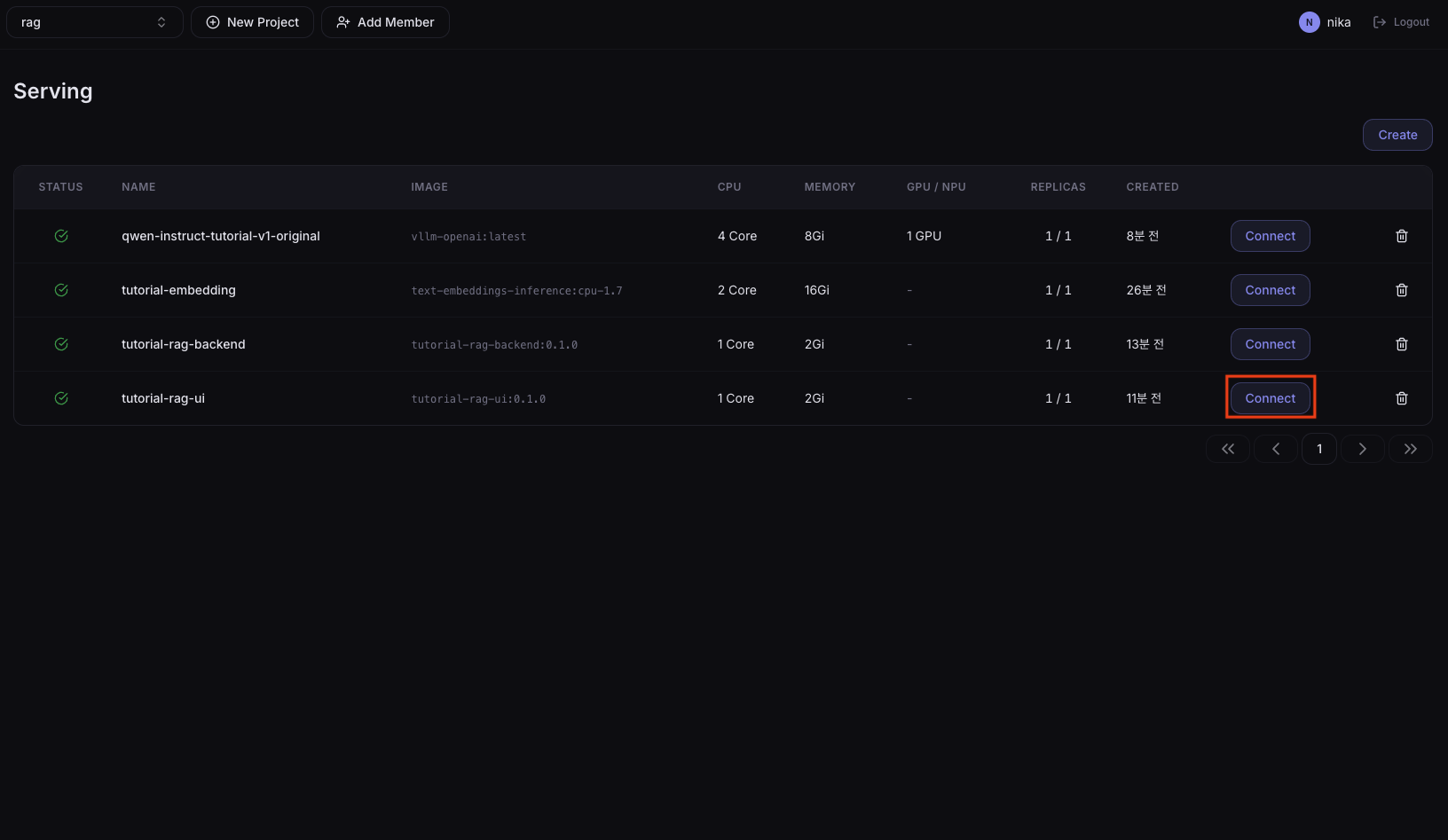
채팅 화면이 열리면, 1단계에서 업로드한 문서와 관련된 질문을 입력해 답변과 출처를 받을 수 있습니다.
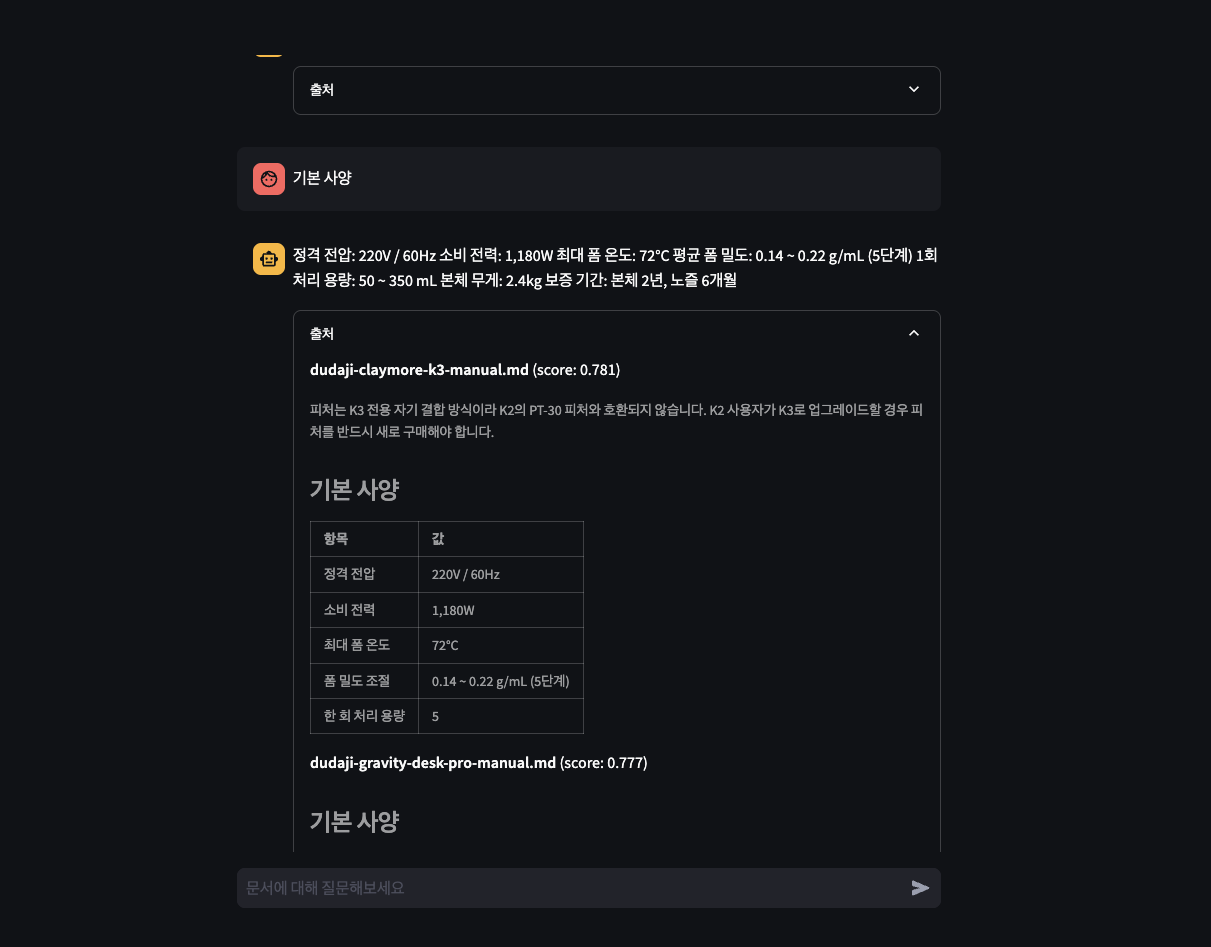
정상 동작하면 응답과 함께 출처 패널에 업로드한 문서명(예: company-guide.md — 앞 단계에서 업로드한 문서 이름)과 score, snippet이 표시됩니다.
현재 튜토리얼에서 배포한 LLM은 Qwen2.5-0.5B-Instruct 입니다. 0.5B급 소형 모델이라 RAG로 검색된 문서를 바탕으로 답변을 만들더라도 답변이 정확하지 않거나 일관성이 떨어질 수 있습니다. 더 정확한 응답이 필요하다면 더 큰 모델로 LLM Serving을 교체해 보세요.