OpenWebUI로 RAG 챗봇 서빙하기
NuFi LLM Serving 앞에 OpenWebUI 를 붙여서, 별도 코드 작성 없이 ChatGPT 스타일의 채팅 화면과 문서 기반 답변(RAG) 을 같이 사용합니다. NuFi Serving이 OpenAI 호환 API(/v1/chat/completions)를 제공하므로 OpenWebUI를 그대로 연결할 수 있고, 문서 검색은 OpenWebUI에 내장된 Knowledge 기능을 사용합니다.
구성
Serving: qwen-instruct-tutorial-v1-original ← OpenAI 호환 LLM 백엔드 (vLLM, 사전 조건에서 배포)
└─ /v1/chat/completions
Volume: openwebui-volume ← OpenWebUI 설정/사용자 DB + 업로드 문서 + 내장 인덱스 저장
└─ /app/backend/data
Serving: tutorial-openwebui ← 외부 노출 지점
└─ ghcr.io/open-webui/open-webui:main
└─ LLM Serving을 OpenAI 호환 백엔드로 연결
└─ Knowledge 컬렉션에 문서 업로드 → 채팅에서 # 으로 참조
OpenWebUI는 사용자 계정, 대화 이력, 업로드한 문서, 내장 임베딩 인덱스를 모두 컨테이너 내부 /app/backend/data에 저장합니다. Pod이 재시작돼도 데이터가 유지되도록 NuFi Volume을 마운트합니다.
사전 조건
- Lab에서 RAG 챗봇 구성하기의 사전 조건에 따라 vLLM 기반 LLM Serving이 Running 상태.
- LLM Serving 배포 시 사용한 모델 ID 확인 (Serving 상세의 Command/Args에서
--model뒤 값) - 테스트용 영어 텍스트 문서 1~2개 (
.md,.txt,.pdf등)
환경변수와 URL에 등장하는 값은 본인 환경에 맞게 바꿔서 사용해야 합니다. 주요 위치는 다음과 같습니다.
- 프로젝트 네임스페이스 — NuFi 대시보드 상단 헤더의 프로젝트 네임스페이스 영역에서 확인할 수 있습니다. 본문에서는
rag라는 가정으로 예시를 작성했습니다. - LLM Serving 이름 — Development > Serving 목록에 표시되는 이름. Quick Deploy 시
<model-name>-<version>-<artifact>형식으로 자동 생성됩니다. 본문에서는 사전 조건에서 준비한qwen-instruct-tutorial-v1-original을 기준으로 예시를 작성했습니다. - OpenWebUI Serving 이름 — 본 튜토리얼에서 직접 입력하는 값으로,
tutorial-openwebui를 사용합니다.
1. OpenWebUI 데이터용 Volume 생성
Volume 생성 절차는 사용 가이드 > 스토리지 > Volume 생성을 참고합니다. 아래 값으로 생성하세요.
| 필드 | 입력값 |
|---|---|
| Volume Name | openwebui-volume |
| Size | 10Gi |
업로드할 문서가 많거나 대화 이력을 길게 유지할 계획이라면 Size를 더 크게 잡아도 됩니다. 생성 후 Volume 목록에서 Ready 상태인지 확인합니다.
OpenWebUI는 사용자 계정·채팅 이력·워크스페이스 설정뿐 아니라 Knowledge에 업로드한 문서와 내장 임베딩 인덱스 까지 모두 /app/backend/data 경로 안에 저장합니다. Volume 없이 띄우면 Pod이 재시작될 때 문서와 인덱스가 전부 날아갑니다.
2. OpenWebUI Serving 배포
Serving 생성 방법과 각 필드 의미는 사용 가이드 > Serving > Serving 생성 문서를 참고하세요. 본문에서는 이 튜토리얼에 필요한 값만 다룹니다.
Development > Serving > Create로 이동하여 OpenWebUI를 배포합니다.
Step 1 — 기본 정보
| 필드 | 입력값 |
|---|---|
| Service Name | tutorial-openwebui |
| Description | OpenWebUI chat UI with Knowledge |
| Service Template | Custom |
Step 2 — 상세 설정
| 필드 | 입력값 |
|---|---|
| Image | ghcr.io/open-webui/open-webui:main |
| CPU | 2 |
| Memory | 8 |
| Accelerator Type | None |
| Replicas | 1 |
| Inference Port | 8080 |
Volume Mount
| 필드 | 입력값 |
|---|---|
| Volume | openwebui-volume |
| Mount Path | /app/backend/data |
Environment Variables
OPENAI_API_BASE_URL=http://qwen-instruct-tutorial-v1-original.rag.svc:80/v1
OPENAI_API_KEY=unused
WEBUI_AUTH=true
ENABLE_OLLAMA_API=false
ENABLE_RAG_HYBRID_SEARCH=true
OPENAI_API_BASE_URL—http://<llm-service-name>.<project-namespace>.svc:80/v1형식의 LLM Serving 내부 호출 URL.<llm-service-name>과<project-namespace>는 사전 조건 안내에 따라 본인 환경 값으로 치환합니다.OPENAI_API_KEY— 임의의 문자열을 넣습니다 (NuFi 내부 Serving은 키 검증을 하지 않음).WEBUI_AUTH—true로 두면 첫 가입자가 자동으로 관리자가 됩니다. 사내 공유용이면 그대로 둡니다.ENABLE_OLLAMA_API— Ollama 백엔드는 사용하지 않으므로 끕니다.ENABLE_RAG_HYBRID_SEARCH— Knowledge 검색을 벡터 + BM25 하이브리드로 수행해 단순 벡터 검색보다 정확도가 올라갑니다.
배포 후 첫 번째 계정으로 가입해 관리자가 된 다음, OpenWebUI Admin Settings > General > Enable New Sign Ups를 꺼서 외부 가입을 차단할 수 있습니다.
배포 후 Development > Serving 목록에서 tutorial-openwebui가 Running 상태가 될 때까지 기다립니다. 첫 시작 시 임베딩 모델을 다운로드하기 때문에 1~3분 정도 걸릴 수 있습니다.
3. OpenWebUI 접속 및 초기 설정
1. Connect URL 열기
Serving 목록에서 tutorial-openwebui를 선택하고 Connect 버튼을 눌러 외부 URL을 엽니다.
2. 관리자 계정 생성
처음 접속하면 회원가입 화면이 뜹니다. 이름, 이메일, 비밀번호를 입력해 첫 계정을 만듭니다. 첫 가입자가 자동으로 관리자가 됩니다.
사용자 정보는 openwebui-volume 안에 들어 있으므로, 비밀번호를 잃어버린 경우 Lab에서 해당 볼륨을 마운트해 사용자 테이블을 직접 손봐야 합니다. 가급적 비밀번호를 안전한 곳에 기록해 두세요.
4. LLM Serving 연결 확인
환경변수(OPENAI_API_BASE_URL)로 이미 연결돼 있어야 합니다. UI에서 확인합니다.
1. 모델 선택 드롭다운 열기
상단 좌측의 모델 선택 드롭다운을 열면 OPENAI_API_BASE_URL이 가리키는 LLM Serving이 노출하는 모델 ID가 보입니다. 사전 조건에서 확인한 --model (또는 --served-model-name) 값과 같은지 확인합니다.
2. 모델이 보이지 않을 때
다음 순서로 점검합니다.
- 우측 상단 내 아바타 → Admin Panel 클릭 → 상단의 Settings 탭 → 좌측 메뉴의 Connections → OpenAI API 항목으로 이동합니다.
- 입력된 URL이 환경변수
OPENAI_API_BASE_URL값과 같은지 확인하고, URL 우측의 새로고침 버튼을 눌러 모델 목록을 다시 가져옵니다. - 그래도 비어 있으면 LLM Serving 상세 → Logs 탭에서 vLLM이 준비됐는지 확인합니다.
5. 한국어 임베딩 안내
OpenWebUI 기본 임베딩 모델은 영어 위주로 학습돼 있어, 한국어 문서를 정확히 검색하려면 별도로 다국어 임베딩 모델로 교체하는 작업이 필요합니다. 이 튜토리얼에서는 해당 과정을 생략하고 영어 문서를 업로드해 동작을 확인합니다.
6. Knowledge 컬렉션 만들기
문서를 묶어 두는 단위가 Knowledge 컬렉션입니다. 한 컬렉션에 여러 파일을 올려두고 채팅에서 컬렉션을 통째로 참조합니다.
- 좌측 사이드바에서 Workspace > Knowledge 로 이동합니다.
- 우측 상단 + New Knowledge 클릭.
Create a knowledge base다이얼로그가 열리면 다음 항목을 입력합니다.- What are you working on? (Name your knowledge base):
tutorial-docs - What are you trying to achieve? (Describe your knowledge base and objectives): 적당히 입력 (예:
Dudaji product manuals)
- What are you working on? (Name your knowledge base):
- Create 버튼 클릭.
7. 문서 업로드
만든 tutorial-docs 컬렉션을 열고 + Add Content 또는 가운데 드롭존에 파일을 끌어다 놓습니다.
- 권장 포맷:
.md,.txt,.pdf(PDF는 OpenWebUI가 내부에서 텍스트 추출) - 한 번에 여러 개 업로드 가능
업로드된 파일은 즉시 청킹·임베딩되어 컬렉션 내부에 적재됩니다. 파일별 Status가 Processed 가 되면 검색에 쓸 수 있습니다.
8. 채팅에서 Knowledge 사용
방법 1 — 일회성으로 컬렉션 참조 (#)
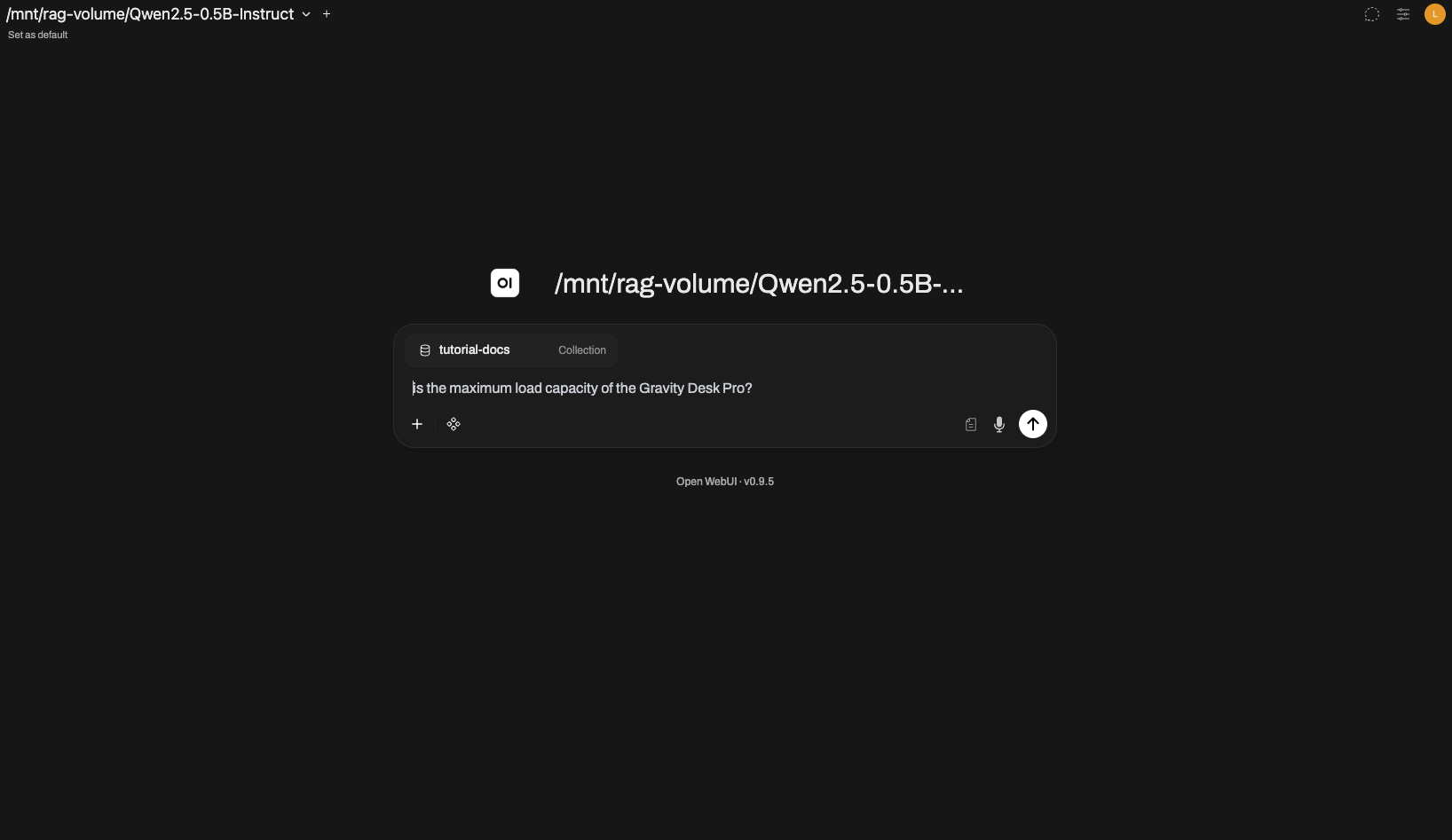
새 채팅에서 메시지 입력창에 # 을 치면 등록된 Knowledge 컬렉션 / 파일 목록이 뜹니다. tutorial-docs 를 선택하고 질문을 작성합니다.
예시 질문 (업로드한 영어 매뉴얼 기준 — 기본 임베딩 모델이 영어 위주이므로 질문도 영어로 작성합니다):
#tutorial-docs What is the maximum load capacity of the Gravity Desk Pro?
#tutorial-docs What does error code E04 on the Claymore K3 mean and how should I handle it?
#tutorial-docs How long does the Claymore K3 self-diagnosis take, and what should I do if the LED blinks red?
#tutorial-docs When does the Gravity Desk Pro require ACS recalibration?
응답이 끝나면 답변 위쪽에 참조한 문서 청크 목록이 펼침으로 표시됩니다. 클릭하면 원문 청크 내용을 확인할 수 있습니다.
방법 2 — 모델에 Knowledge를 영구 연결
매 채팅마다 #을 치는 게 번거롭다면 모델 단위로 컬렉션을 묶어 둘 수 있습니다.

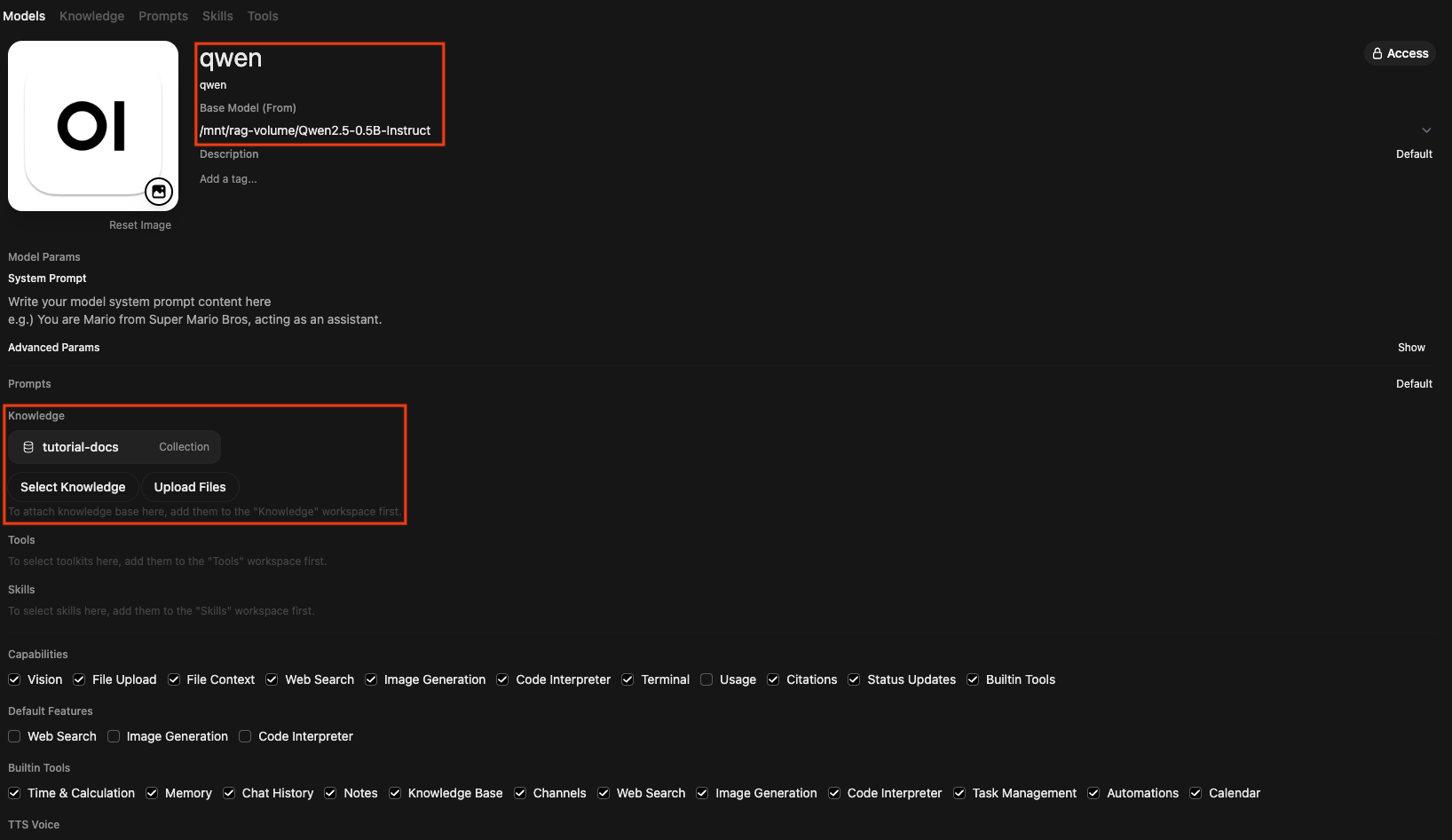
- Workspace > Models > + New Model 클릭.
- Base Model (From) 에서 LLM Serving이 노출한 모델을 선택 (예:
/mnt/rag-volume/Qwen2.5-0.5B-Instruct). - Name:
qwen으로 입력합니다. - Knowledge 섹션의 Select Knowledge 를 눌러
tutorial-docs컬렉션을 추가. - 우측 상단 Save & Create 클릭.
이제 채팅 상단 모델 드롭다운에서 qwen 을 고르면 모든 메시지가 자동으로 tutorial-docs 컬렉션을 거쳐 RAG로 답합니다.
9. 응답 + 출처 확인
업로드한 문서와 관련된 질문을 던지고 답변 + 참조한 문서를 확인합니다.
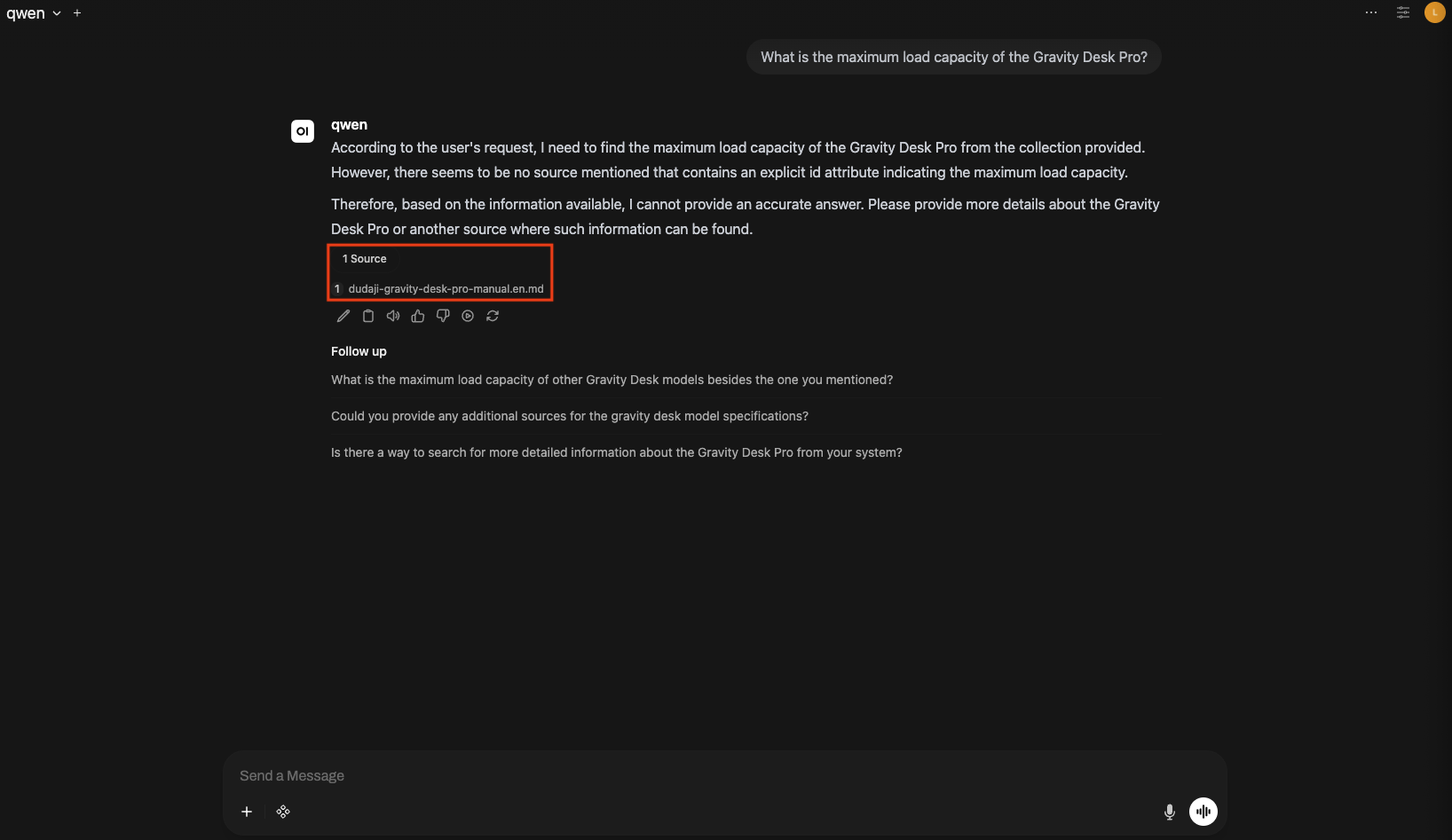
- 답변 본문은 LLM Serving이 생성합니다.
- 답변 영역에 Source 버튼이 함께 표시됩니다.
- Source 버튼을 클릭하면 답변을 만들 때 참조한 문서 청크(파일명, 본문 일부)를 확인할 수 있습니다.
E2E 튜토리얼에서 배포한 Qwen2.5-0.5B-Instruct 는 0.5B급 소형 모델이라 RAG로 검색된 문서를 가져오더라도 답변이 정확하지 않거나 형식이 흔들릴 수 있습니다. 더 큰 모델로 LLM Serving을 교체하면 체감 품질이 크게 좋아집니다.