MLflow 모델 Import로 서빙하기
MLflow Tracking Server의 Run artifact를 NuFi로 가져와 Model Artifacts에 등록하고 Serving으로 배포합니다. 이미 MLflow에서 학습과 모델 저장을 관리하고 있는 경우에 사용합니다.
사전 조건
- NuFi 클러스터에서 접근 가능한 MLflow Tracking Server가 필요합니다.
- 모델 파일을 저장할 Volume이 필요합니다. 새 Volume이 필요하면 Volumes를 참고하세요.
- 가져올 MLflow Run ID와 MLflow artifact path를 확인해 둡니다.
1. MLflow Import 실행
좌측 사이드바에서 Model Artifacts를 클릭하고 Integration으로 이동합니다. MLflow 탭에서 Import from MLflow를 클릭합니다.
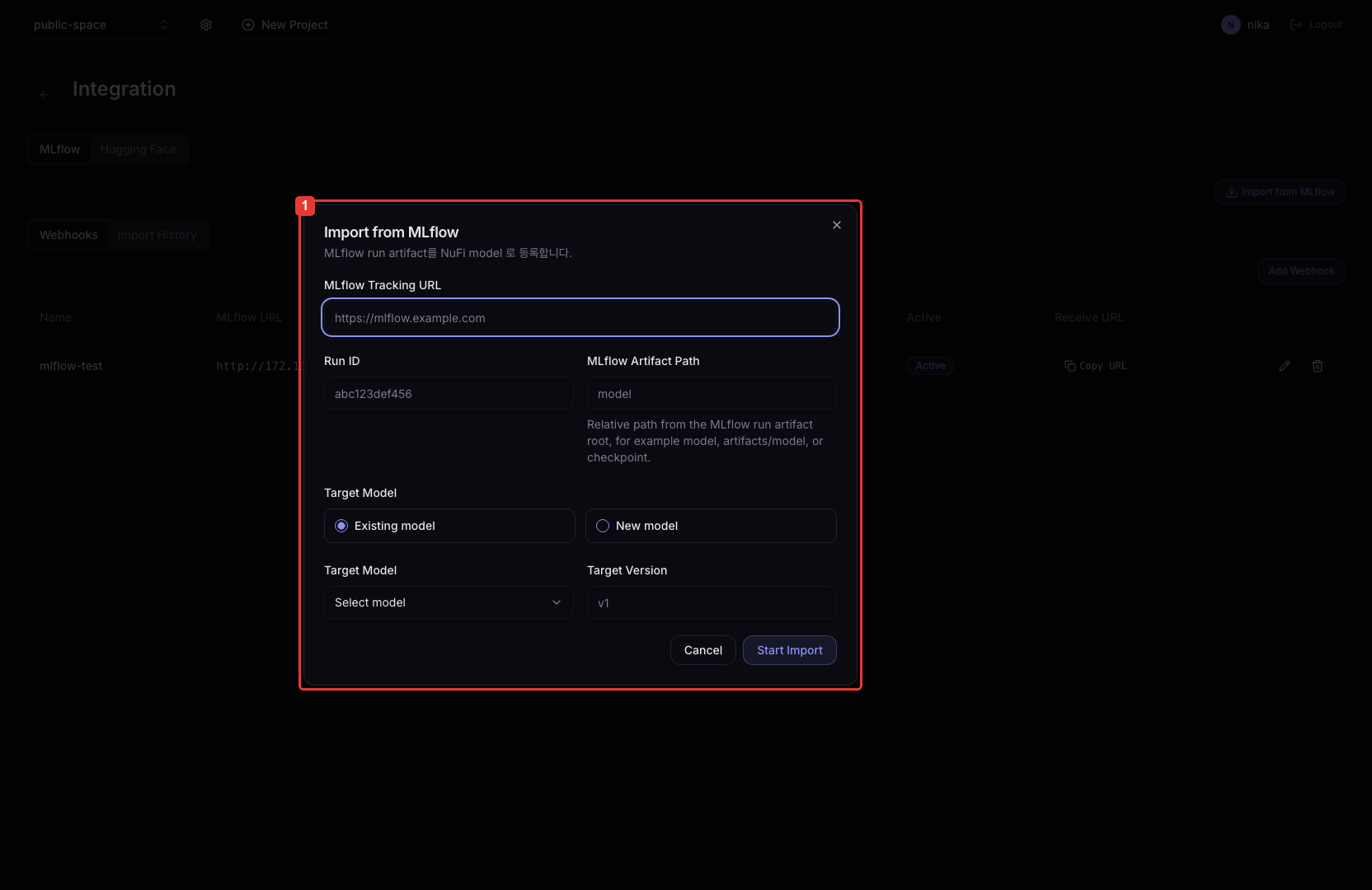
| 필드 | 예시 값 | 설명 |
|---|---|---|
| MLflow Tracking URL | http://mlflow.example.com | MLflow Tracking Server 주소 |
| Run ID | 7f3... | 가져올 MLflow Run UUID |
| MLflow Artifact Path (optional) | model | Run 내 특정 아티팩트 경로. 비워두면 Run 전체를 가져옵니다 |
| Target Model | mlflow-tutorial-model | NuFi에 등록할 모델 이름 |
| Target Version | v1 | 등록할 버전 |
| Storage PVC | tutorial-volume | 아티팩트를 저장할 Volume |
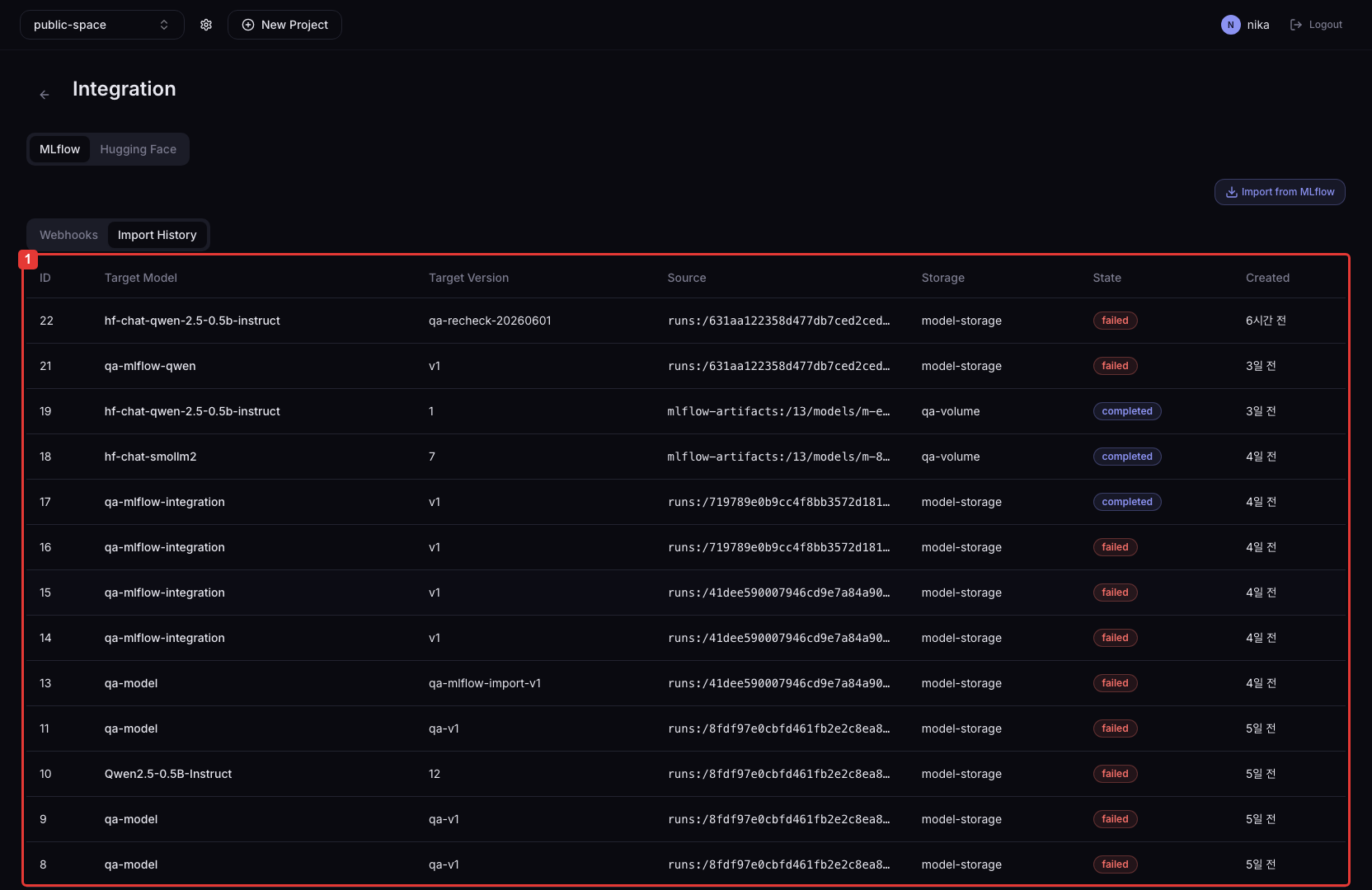
2. Import 완료 확인
Import History에서 작업 상태가 Succeeded인지 확인합니다. 완료되면 선택한 Volume에 모델 파일이 저장되고 Model Artifacts에 모델 버전이 생성됩니다.
3. 서빙 방식 선택
GPU로 바로 서빙하려면 모델 상세에서 Quick Deploy를 실행합니다.
NPU로 서빙하려면 먼저 Model Compilations에서 원본 아티팩트를 컴파일합니다. 컴파일이 Succeeded가 되면 생성된 NPU 아티팩트로 Quick Deploy를 실행합니다.
4. Serving 생성
Quick Deploy 다이얼로그에서 배포할 모델, 버전, 아티팩트를 확인하고 Serving 이름을 입력합니다.
| 필드 | 예시 값 |
|---|---|
| Service Name | mlflow-import-serving |
| Version | v1 |
| Artifact | GPU 서빙은 원본 아티팩트, NPU 서빙은 컴파일된 아티팩트 |
Serving 목록에서 상태가 Running으로 바뀌면 배포가 완료된 것입니다.
다음 단계
서빙 모델의 응답을 확인하려면 Playground에서 응답 테스트하기를 진행하세요.
디바이스 및 노드 메트릭을 확인하려면 Monitoring에서 지표 확인하기를 진행하세요.