모델 배포하기
AI 모델을 NPU/GPU 기반 추론 서비스로 배포하고 관리하는 방법을 안내합니다.
Deployment 목록
좌측 사이드바에서 Deployment를 클릭합니다.
| 버튼 | 설명 |
|---|---|
| Create | 새 Deployment 생성 |
| Connect | 동적 Endpoint 접속 |
| Playground | 채팅 UI로 모델 테스트 |
| Delete | Deployment 삭제 |
Deployment 생성
Create 버튼을 눌러 생성 페이지로 이동합니다. 생성은 3단계로 진행됩니다.
- Step 1. 기본 정보
- Step 2. 상세 설정
- Step 3. 리뷰 & 배포
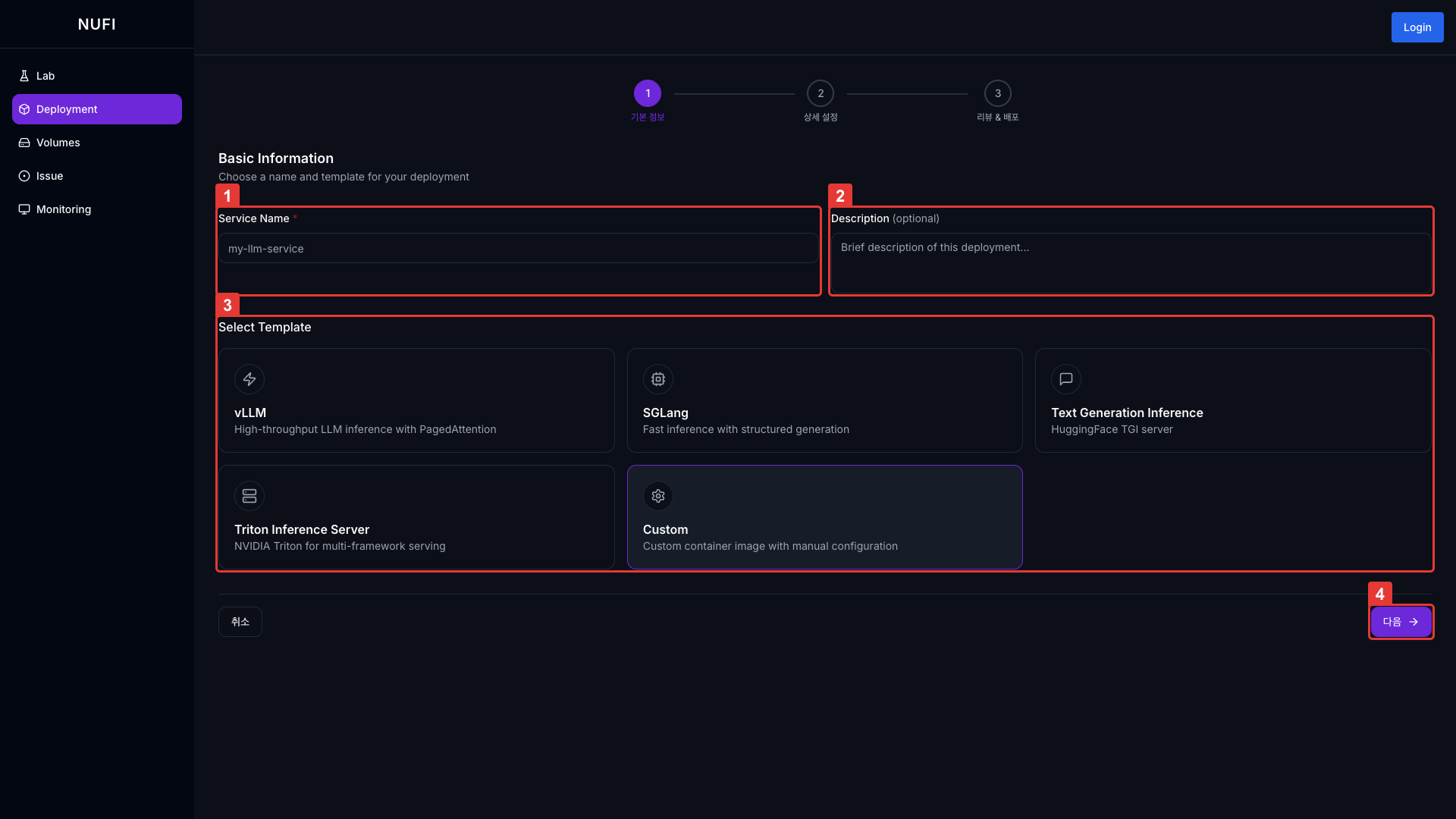
| 필드 | 설명 | 필수 |
|---|---|---|
| Service Name | Deployment 이름 (소문자, 숫자, 하이픈, 최대 63자) | ✓ |
| Description | Deployment 설명 | - |
| Service Template | 추론 프레임워크 선택 | ✓ |
공통 설정:
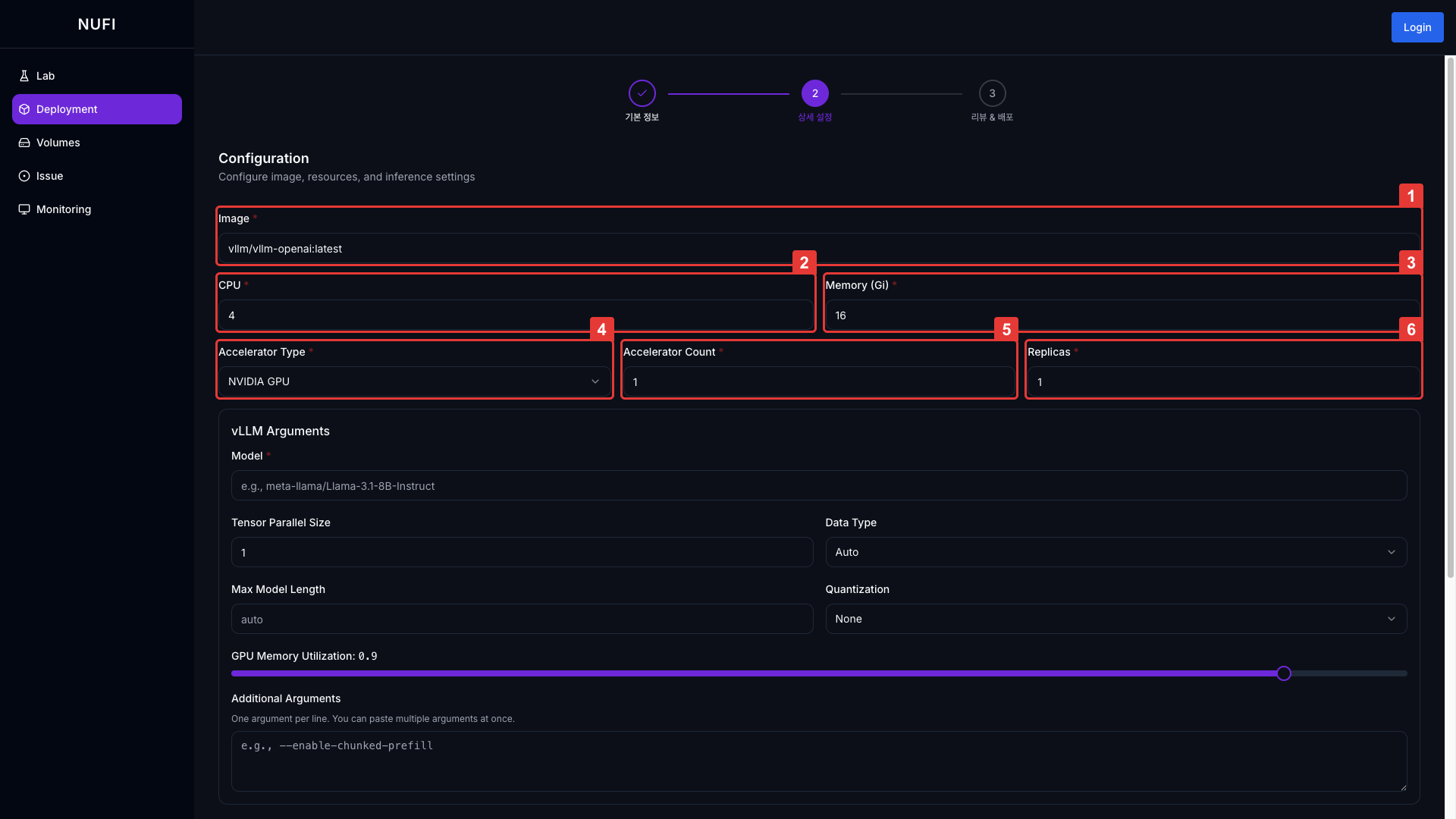
| 필드 | 설명 | 기본값 |
|---|---|---|
| Image | 컨테이너 이미지 | - |
| CPU | CPU 코어 수 | 0.5 |
| Memory | 메모리 (GiB) | 1.0 |
| Accelerator Type | 가속기 유형 | None |
| Accelerator Count | 가속기 개수 | 1 |
| Replicas | 서비스 컨테이너 개수 | 1 |
Advanced Settings (선택):
| 필드 | 설명 | 기본값 |
|---|---|---|
| Inference Port | 서비스 추론 포트 | 8000 |
| Command Override | 컨테이너 시작 명령어 | - |
| Environment Variables | 환경변수 (KEY=VALUE 또는 env file) | - |
| Transformer | 전/후처리 사이드카 추가 | - |
템플릿별 추가 설정:
- vLLM
- SGLang
- TGI
- Triton
- Custom
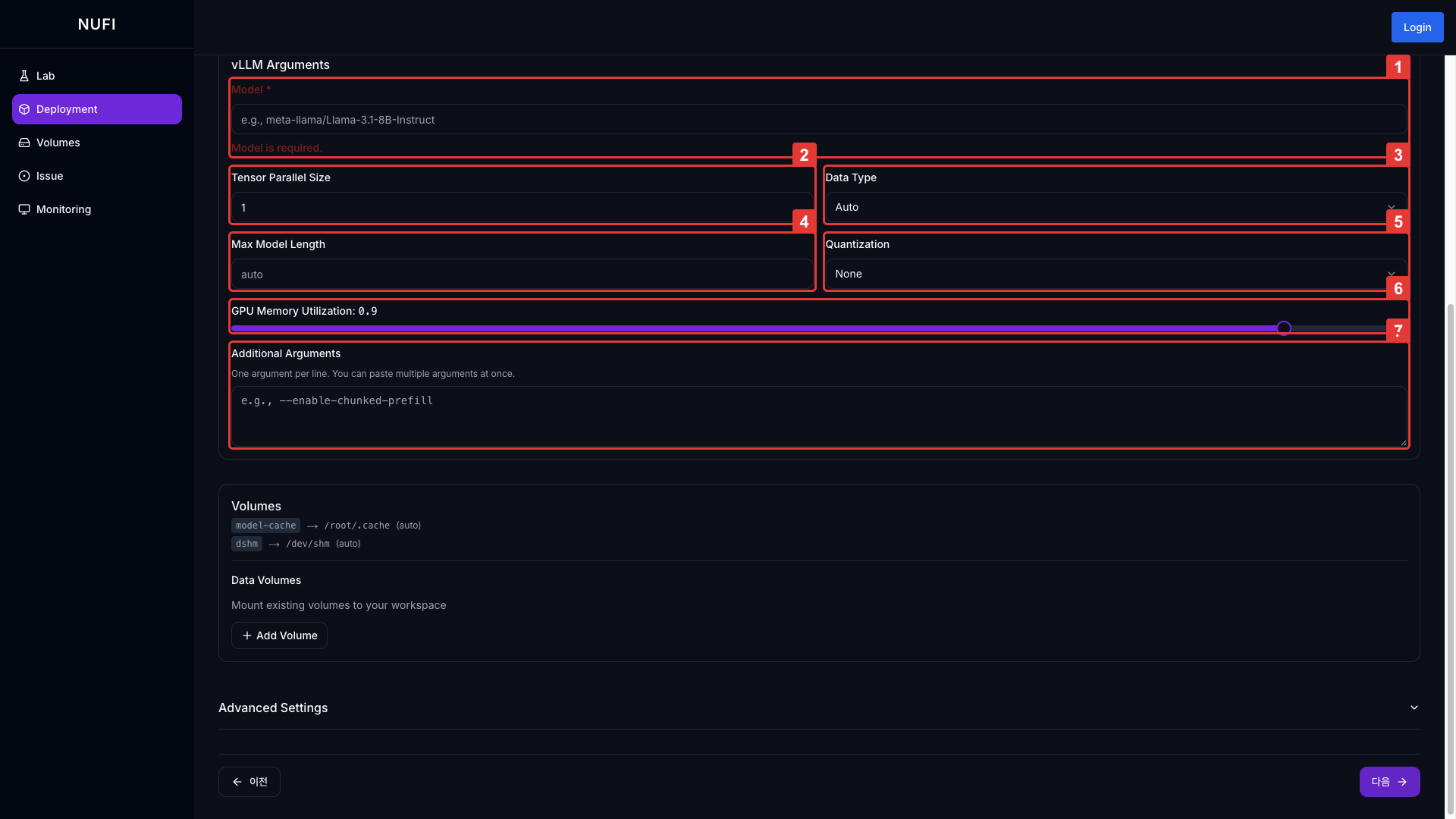
| 필드 | 설명 | 기본값 |
|---|---|---|
| Model | 모델 이름 또는 경로 (예: meta-llama/Llama-3.1-8B-Instruct) | - |
| Tensor Parallel Size | 모델을 나눠 올릴 GPU 수 | 1 |
| Data Type | 모델 연산 숫자 표현 방식 | Auto |
| Max Model Length | 최대 처리 토큰 수 (입력+출력 합산) | - |
| Quantization | 모델 정밀도 낮춰 메모리 절약 | - |
| GPU Memory Utilization | vLLM이 사용할 GPU 메모리 비율 (0.0~1.0) | 0.9 |
| Additional Arguments | vLLM 고급 설정 직접 입력 | - |
| 필드 | 설명 | 기본값 |
|---|---|---|
| Model | 모델 이름 또는 경로 | - |
| Tensor Parallel Size | 모델을 나눠 올릴 GPU 수 | 1 |
| Data Type | 모델 연산 숫자 표현 방식 | Auto |
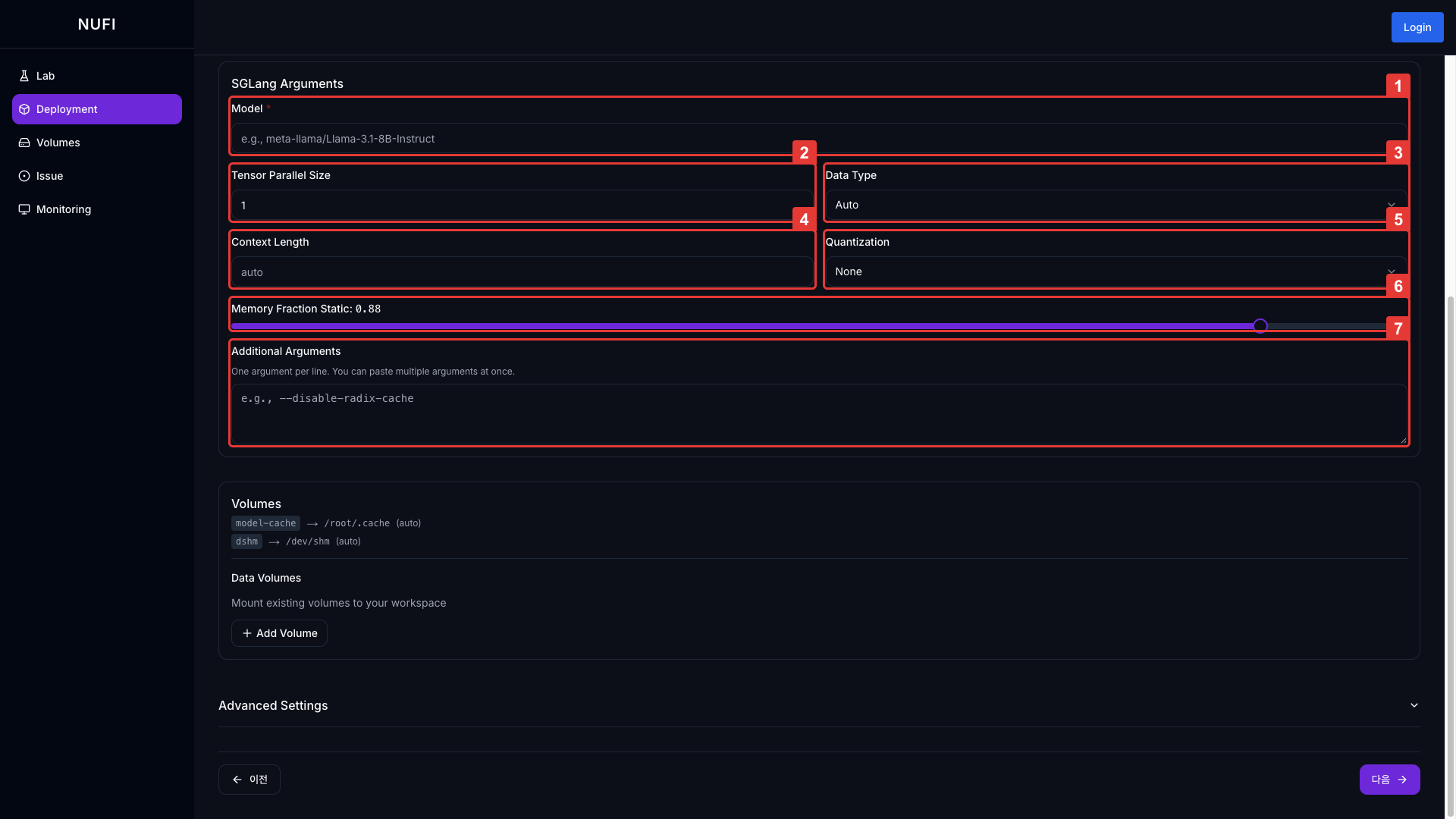
| Context Length | 최대 입력 문맥 토큰 수 | - |
| Quantization | 모델 정밀도 낮춰 메모리 절약 | - |
| Memory Fraction Static | 모델 실행에 예약할 GPU 메모리 비율 (0.0~1.0) | 0.88 |
| Additional Arguments | SGLang 고급 설정 직접 입력 | - |
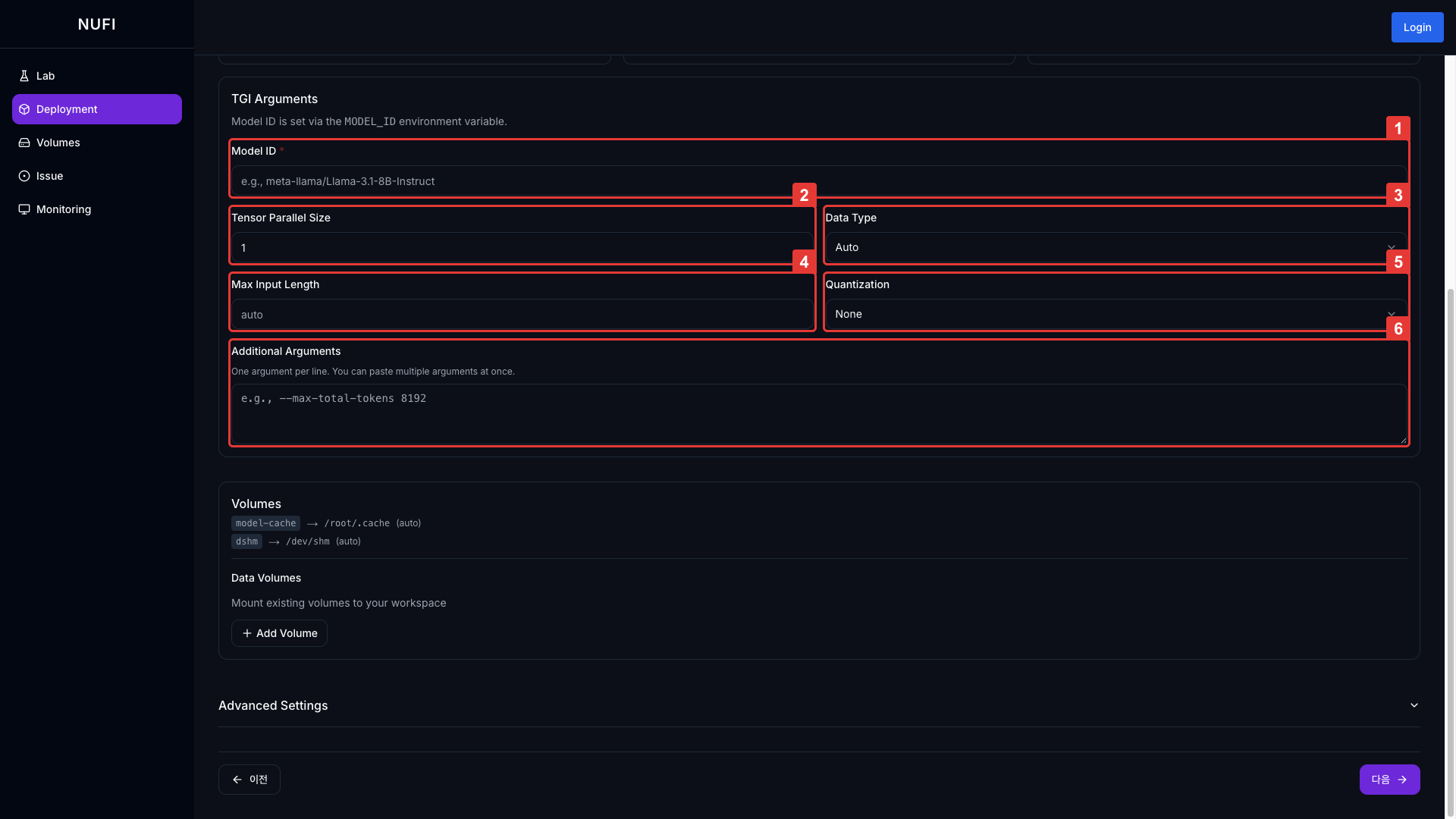
| 필드 | 설명 | 기본값 |
|---|---|---|
| Model ID | HuggingFace 모델 ID | - |
| Tensor Parallel Size | 모델을 나눠 올릴 GPU 수 | 1 |
| Data Type | 모델 연산 숫자 표현 방식 | Auto |
| Max Input Length | 최대 입력 토큰 수 | - |
| Quantization | 모델 정밀도 낮춰 메모리 절약 | - |
| Additional Arguments | TGI 고급 설정 직접 입력 | - |
Triton Inference Server는 공통 설정(Image, CPU, Memory, Accelerator, Replicas)만 사용합니다. 템플릿별 추가 필드가 없습니다.
Custom 템플릿은 공통 설정(Image, CPU, Memory, Accelerator, Replicas)과 Advanced Settings만 사용합니다. 컨테이너 이미지와 Command Override로 직접 제어합니다.
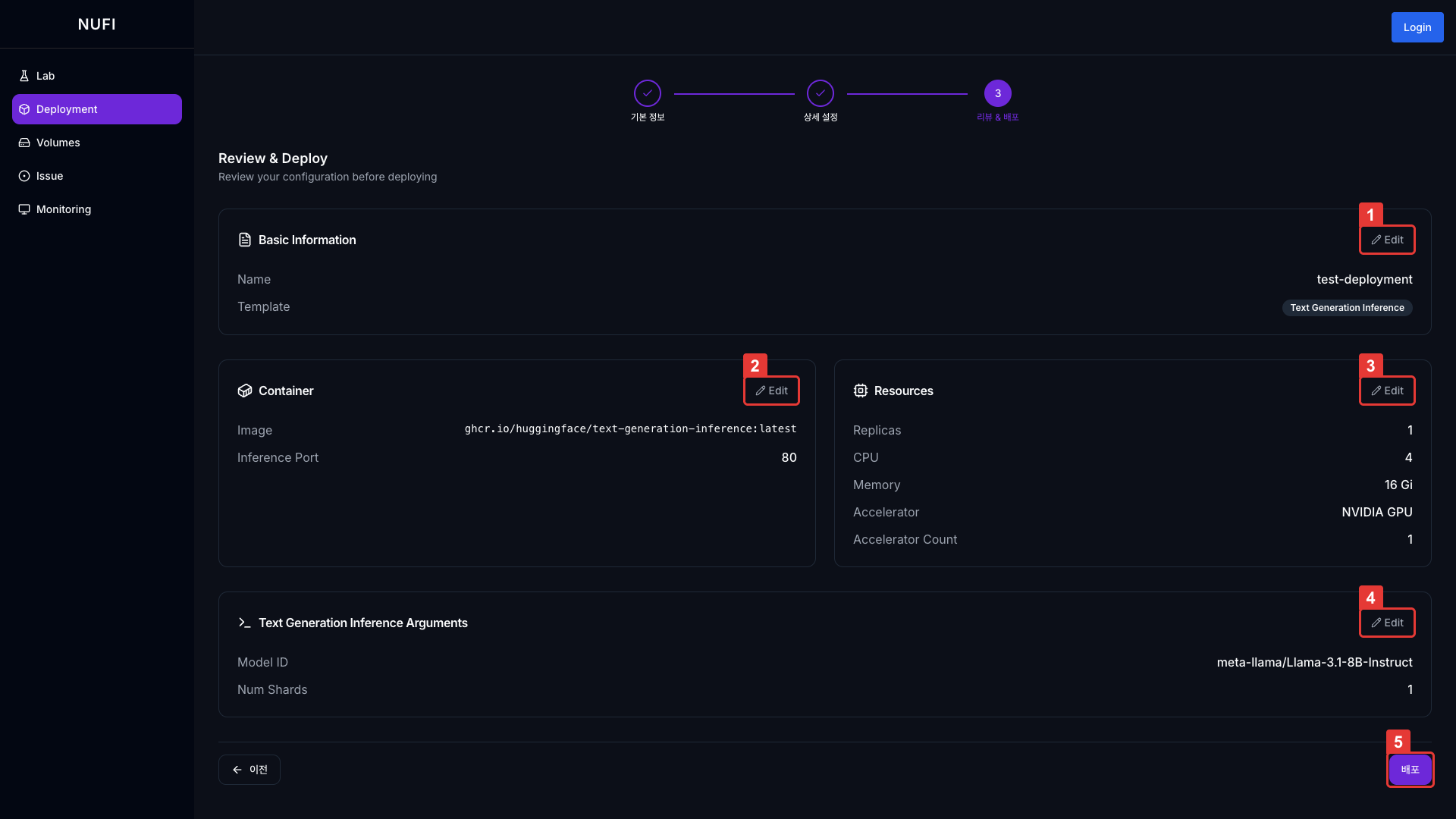
수정할 스펙이 있으면 Edit 버튼으로 수정합니다. 우측 하단 배포 버튼을 클릭하여 배포합니다.
Deployment 상세 페이지
Deployment 목록에서 항목을 클릭하면 상세 페이지로 이동합니다.
- Overview
- Metrics
- Logs
- Async Queue
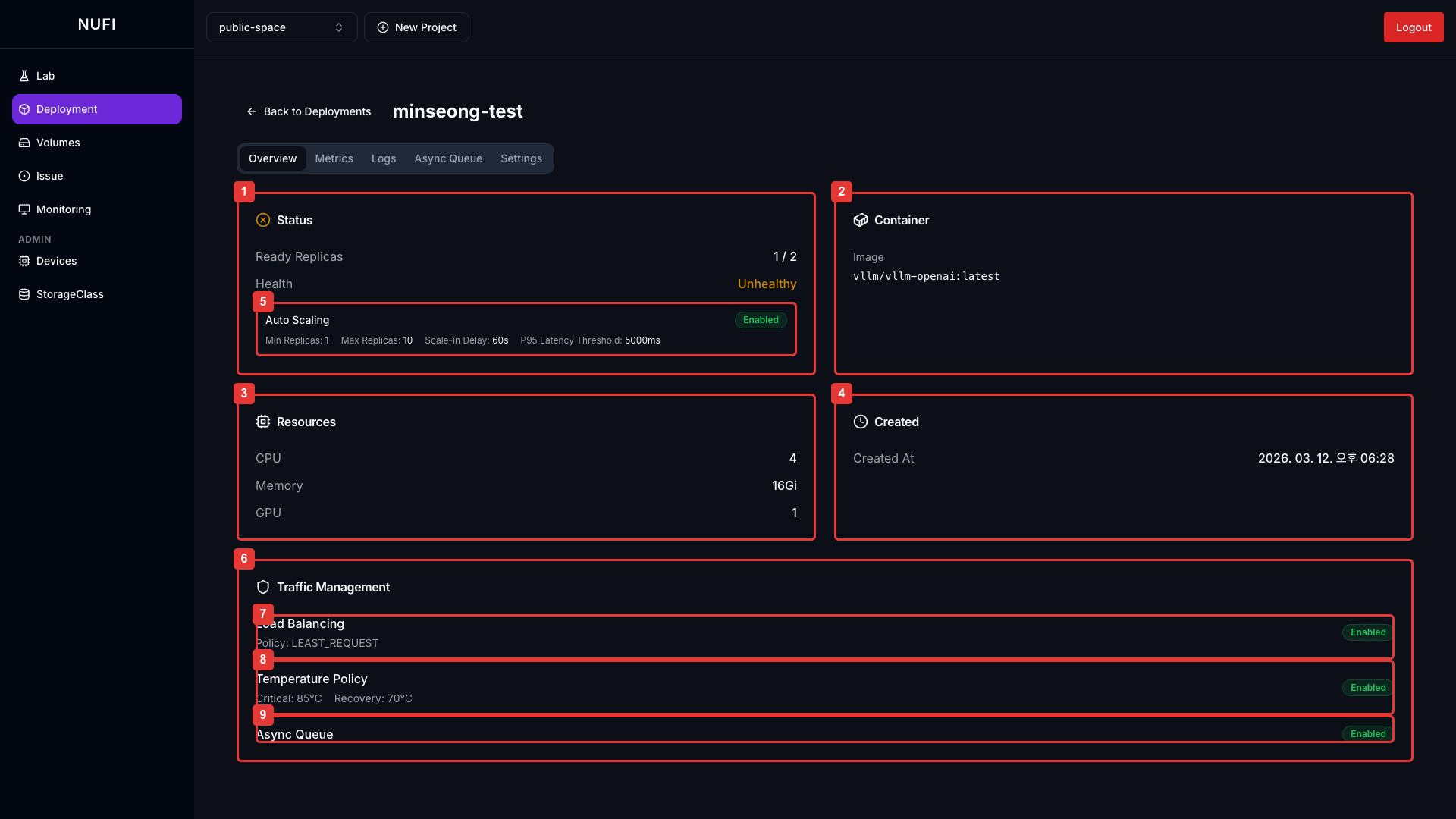
| 카드 | 정보 |
|---|---|
| Status | Ready Replicas, Health 상태 |
| Container | 사용 중인 이미지 |
| Resources | CPU, Memory, GPU/NPU 정보 |
| Created | 생성 시간 |
| Auto Scaling | 자동 스케일링 설정 (Settings에서 활성화 시 출력) |
| Traffic Management | 트래픽 관리 설정 카드 |
| Load Balancing | 로드밸런싱 설정 (Settings에서 활성화 시 출력) |
| Temperature Policy | 온도 기반 트래픽 제어 (Settings에서 활성화 시 출력) |
| Async Queue | 비동기 요청 설정 (Settings에서 활성화 시 출력) |
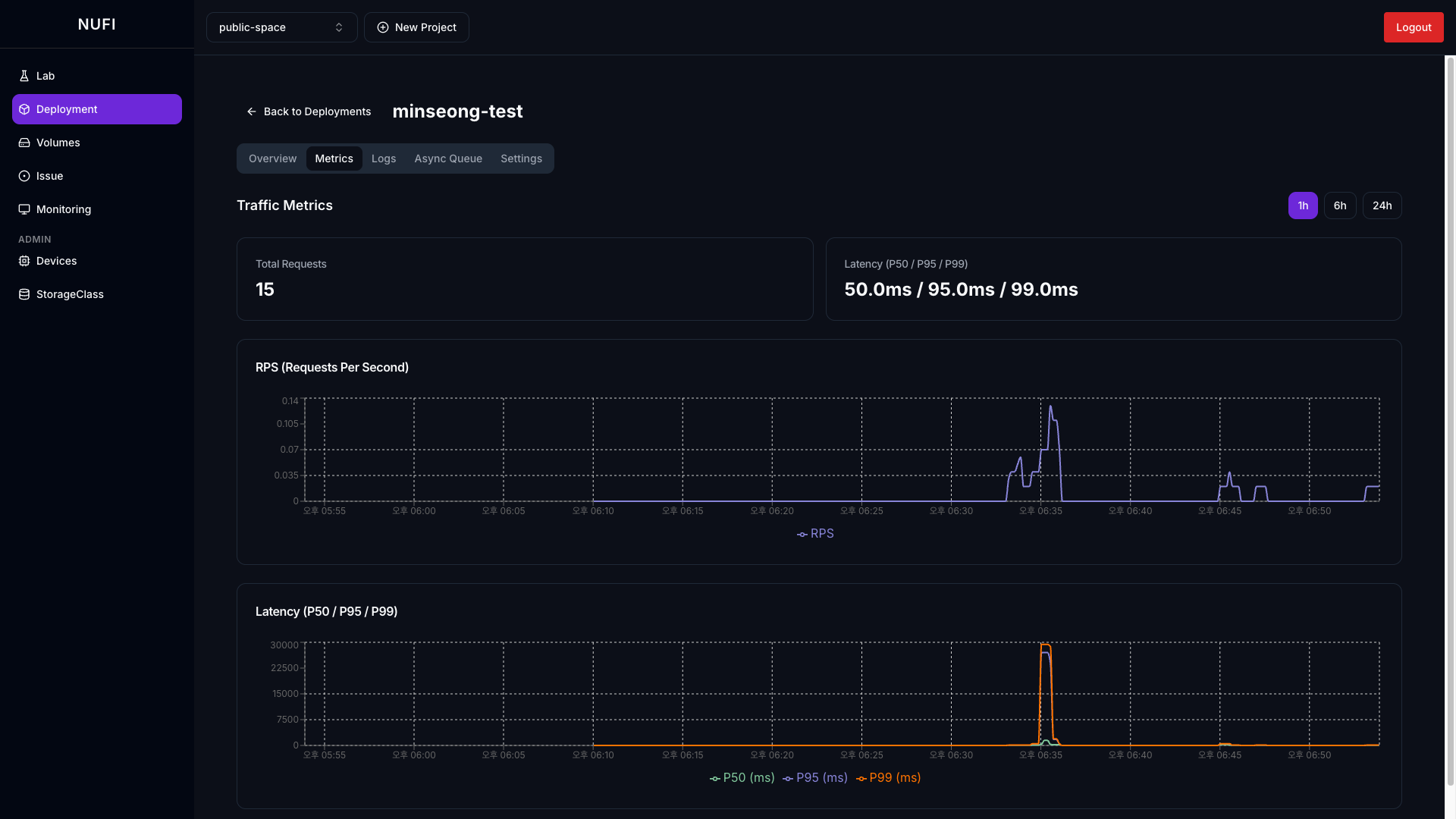
우측 상단 시간 범위 버튼(1h / 6h / 24h)으로 그래프 기간을 조절할 수 있습니다.
| 카드 | 정보 |
|---|---|
| Total Requests | 전체 요청 횟수 |
| Latency (P50 / P95 / P99) | 현재 요청 응답 시간 |
| RPS 그래프 | 초당 요청 개수 시계열 |
| Latency 그래프 | P50/P95/P99 응답 시간 시계열 |
추론 서버 컨테이너의 실행 로그를 출력합니다.
Settings에서 Async Queue를 활성화하면 비동기 요청 목록과 처리 결과를 조회합니다.
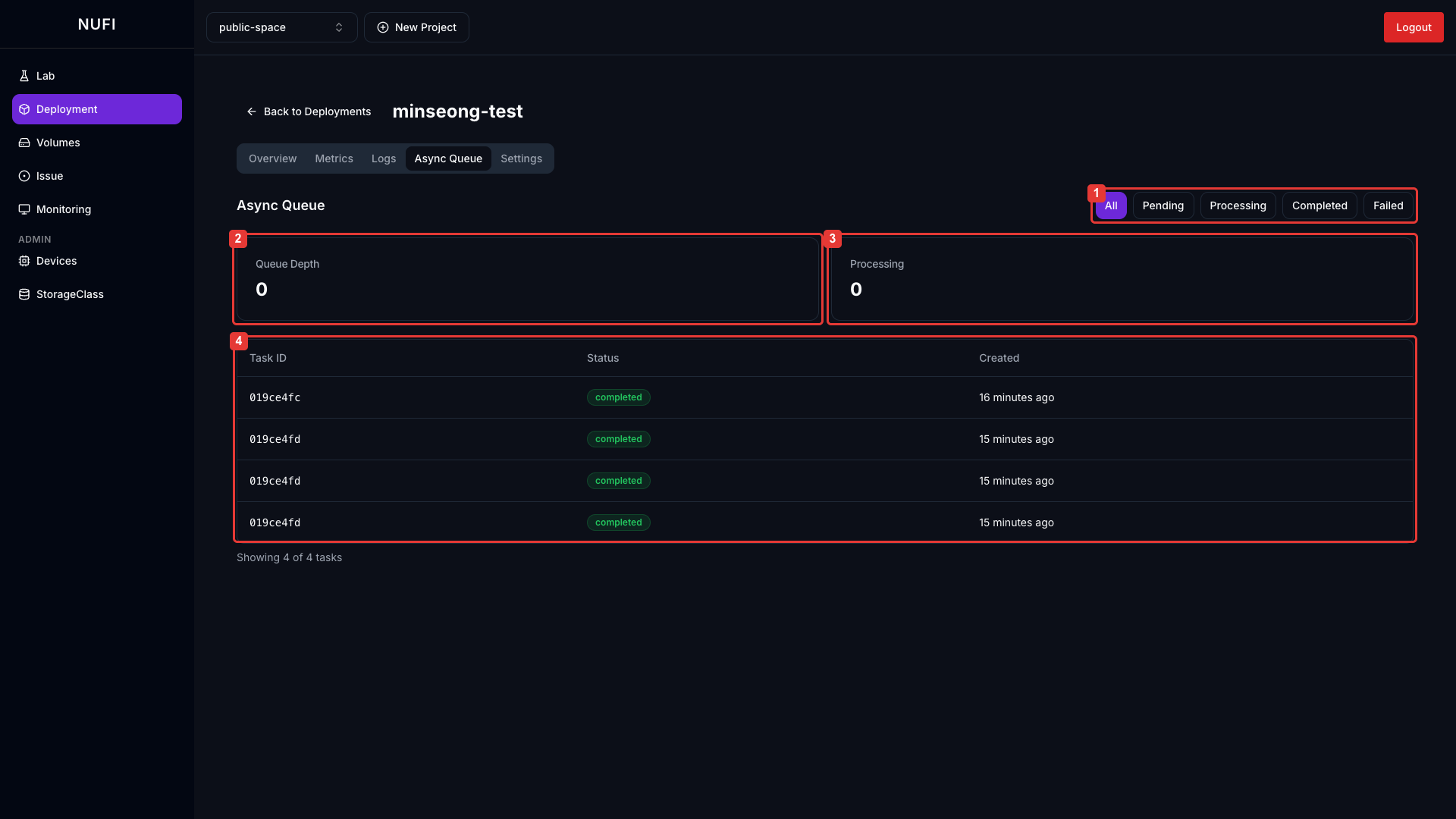
| 항목 | 설명 |
|---|---|
| 상태 필터 | All / Pending / Processing / Completed / Failed |
| Queue Depth | 현재 Queue에 쌓인 Task 수 |
| Processing | 현재 진행 중인 Task 수 |
특정 Task를 클릭하면 Request / Response 상세 정보를 확인할 수 있습니다.
비동기 요청 방법 — HTTP 요청 시 X-Async: true 헤더를 추가합니다.
curl -X POST 'https://<deployment-endpoint>/v1/chat/completions' \
-H 'Content-Type: application/json' \
-H 'X-Async: true' \
-d '{"model": "모델명", "messages": [{"role": "user", "content": "안녕하세요"}]}'
네이밍 규칙
- 소문자 영문, 숫자, 하이픈(-) 사용 가능
- 하이픈으로 시작하거나 끝날 수 없음
- 최대 63자 (Kubernetes 제한)
예시: my-model-v1, llm-server-prod
지원 가속기
| 가속기 | 리소스 키 | 사용 가능 기능 |
|---|---|---|
| NVIDIA GPU | nvidia.com/gpu | Lab, Deployment |
| Rebellions ATOM | rebellions.ai/ATOM | Lab, Deployment |
| Furiosa RNGD | furiosa.ai/rngd | Lab, Deployment |