배포 고급 설정
Deployment 상세 페이지의 Settings 탭에서 추론 서버, 트래픽, Transformer를 설정합니다.
- Inference Server
- Traffic Management
- Transformer
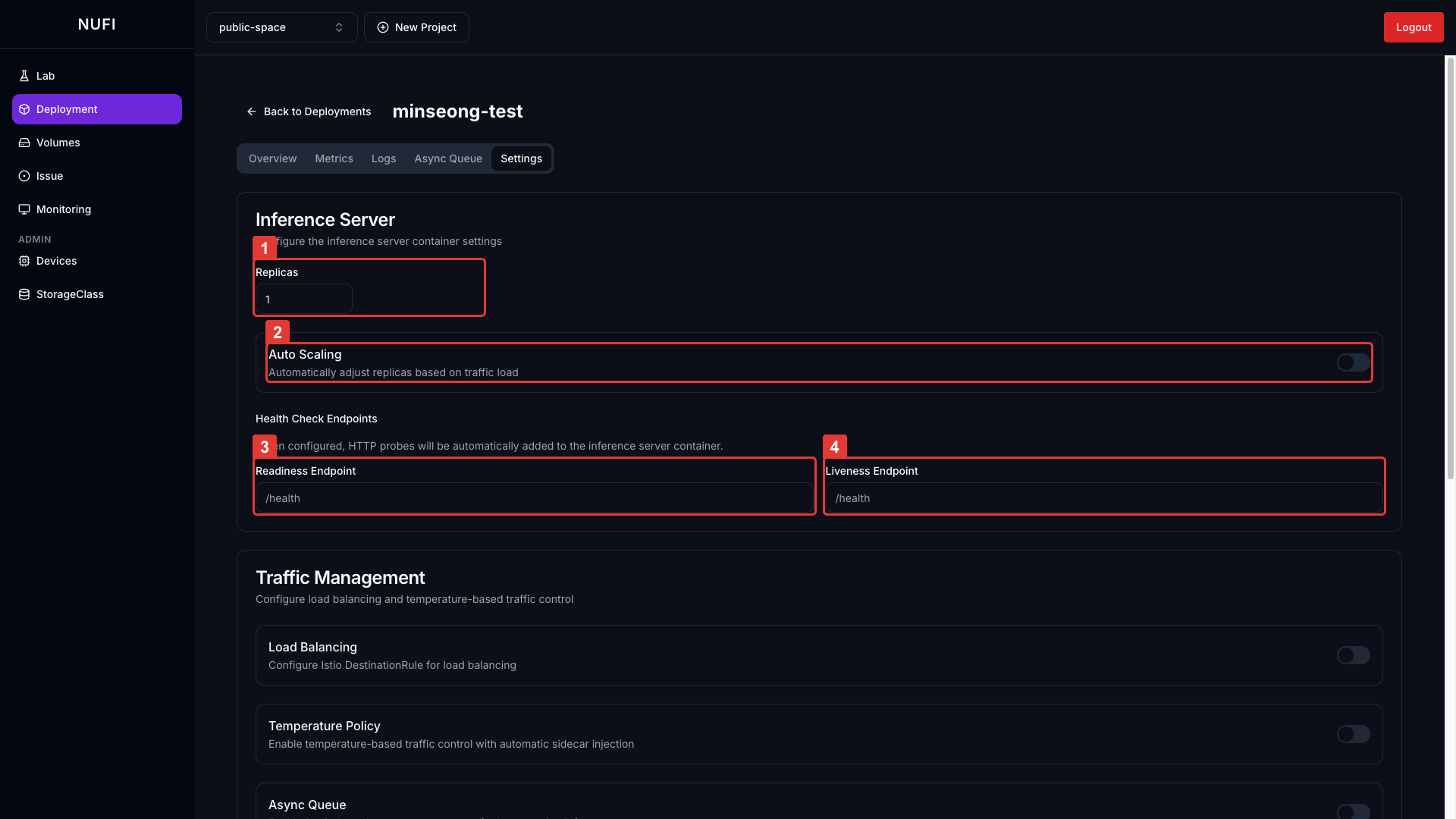
| 설정 | 설명 | 기본값 |
|---|---|---|
| Replicas | 레플리카 수 조정 | 1 |
| Auto Scaling | 트래픽 부하에 따라 Pod 수 자동 조절 | Off |
| Readiness Endpoint | Pod가 트래픽 받을 준비 여부 확인 엔드포인트 | - |
| Liveness Endpoint | Pod 정상 동작 여부 확인. 반복 실패 시 자동 재시작 | - |
Auto Scaling 활성화 시 추가 설정:
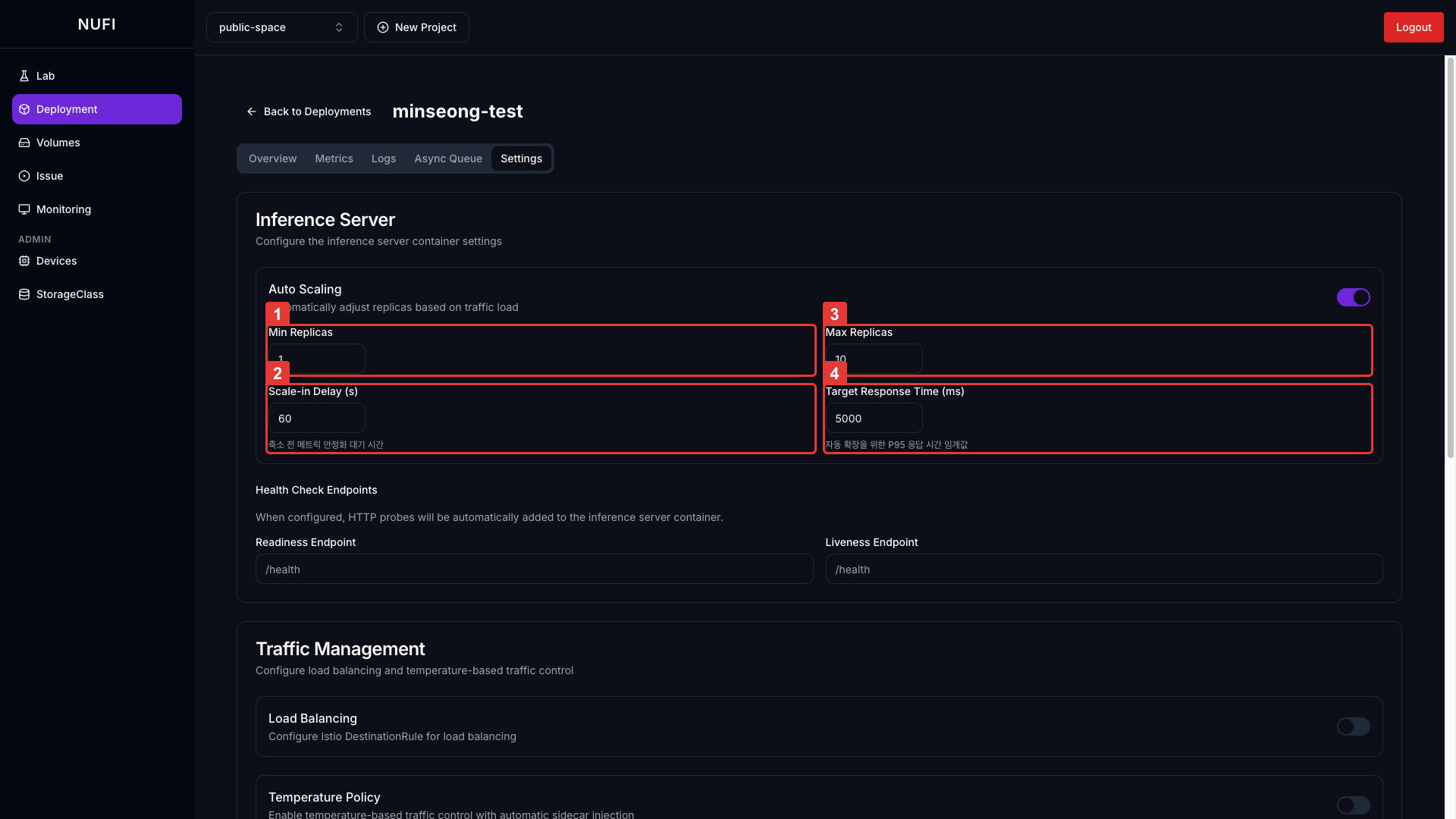
| 설정 | 설명 | 기본값 |
|---|---|---|
| Min Replicas | 항상 유지할 최소 Pod 수 | 1 |
| Scale-in Delay (s) | 트래픽 감소 후 Pod 축소까지 대기 시간 (flapping 방지) | 60 |
| Max Replicas | 최대 Pod 수 (클러스터 가속기 여유분 고려 필요) | 10 |
| Target Response Time (ms) | 자동 확장 기준 P95 응답 시간 목표값. 초과 시 Pod 증가 | 5000 |
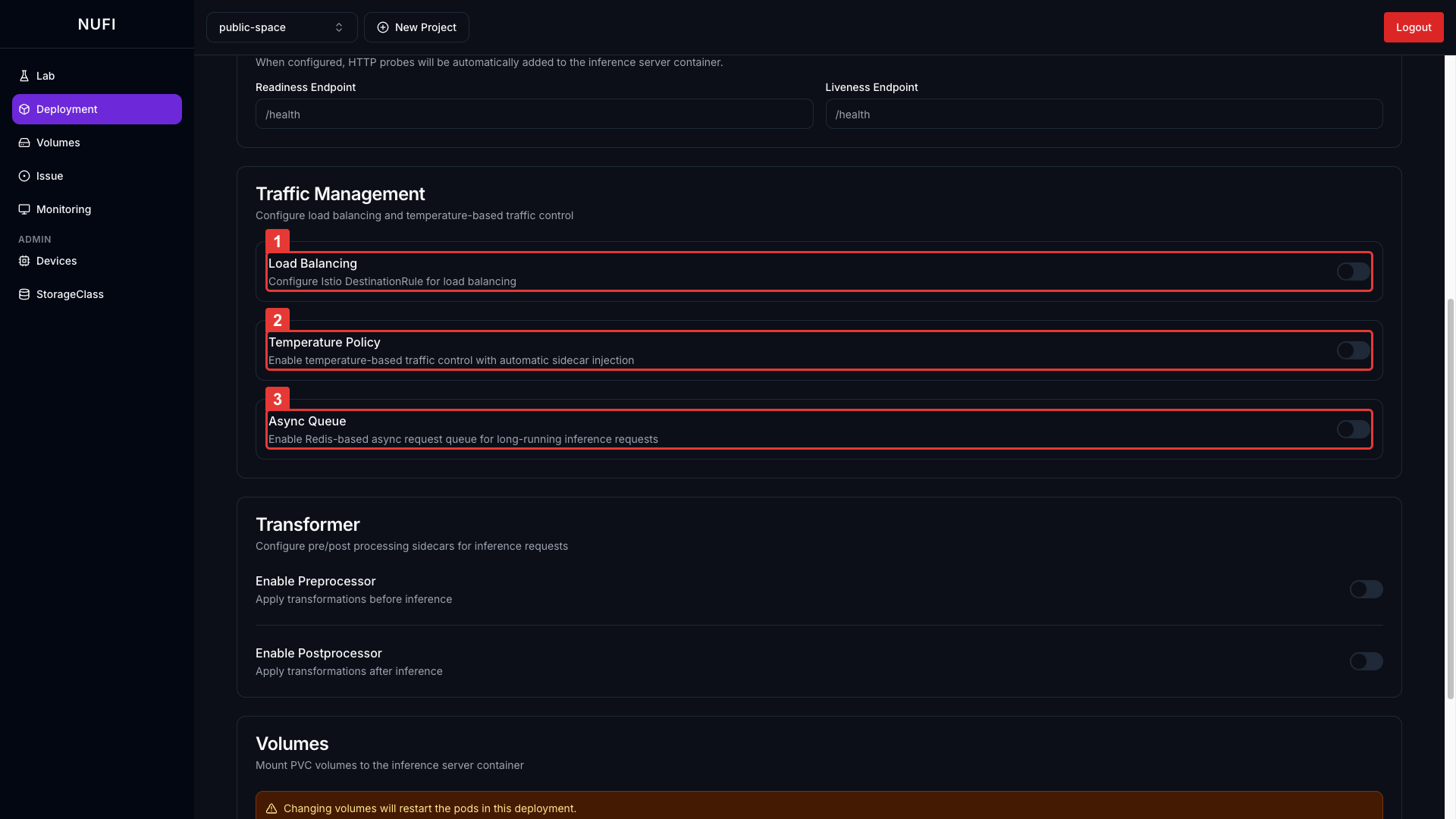
| 기능 | 설명 | 기본값 |
|---|---|---|
| Load Balancing | 여러 Pod로 요청 분산 | Off |
| Temperature Policy | GPU/NPU 온도 임계값 초과 시 해당 Pod 트래픽 자동 차단, 회복 시 재개 | Off |
| Async Queue | Redis 기반 비동기 요청 큐 활성화 | Off |
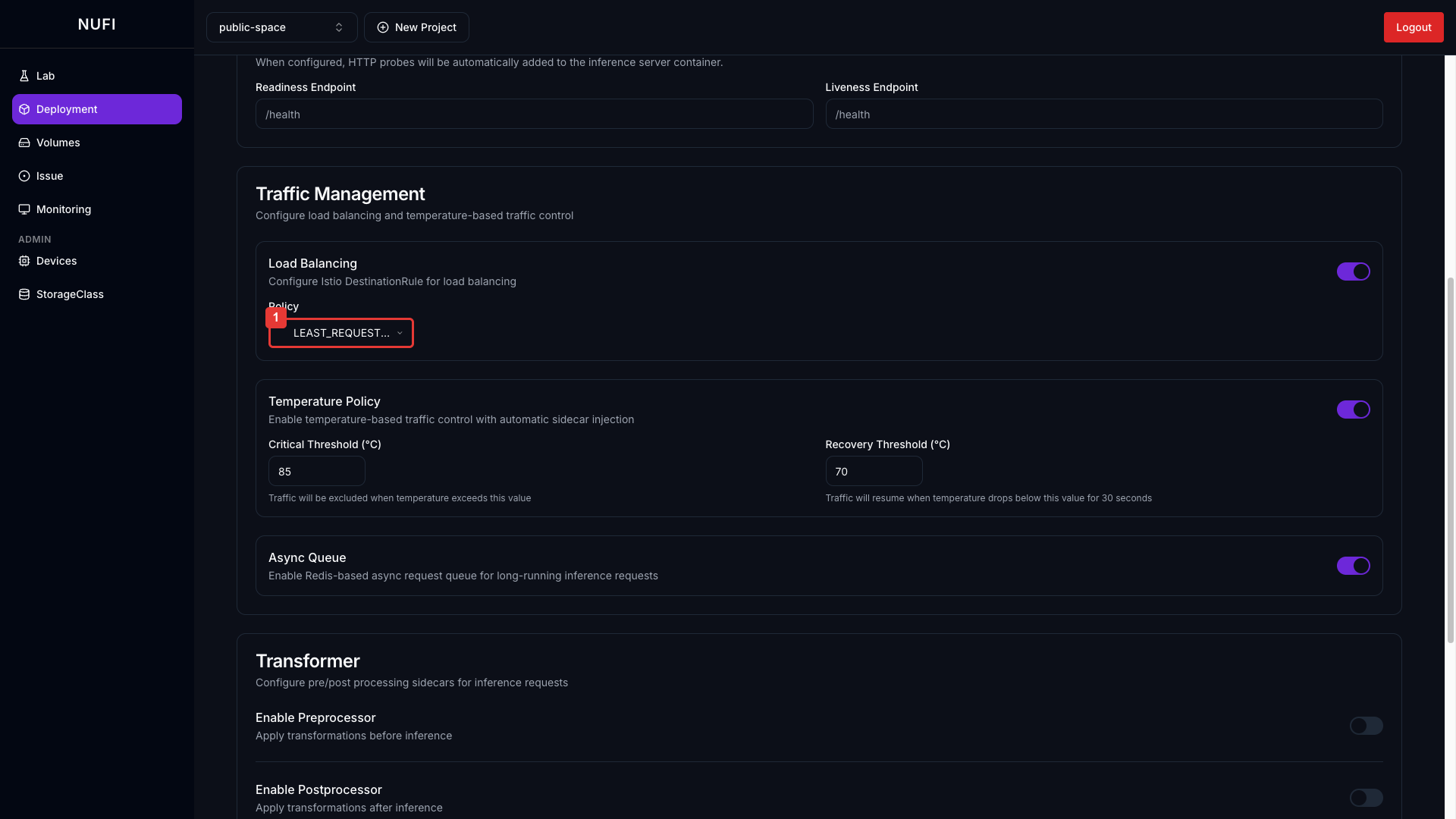
Load Balancing 활성화 시 Policy 드롭다운이 나타납니다:
| 옵션 | 설명 |
|---|---|
| LEAST_REQUEST (기본값) | 활성 요청 수가 가장 적은 Pod로 라우팅 |
| ROUND_ROBIN | Pod들을 순서대로 돌아가며 라우팅 |
| RANDOM | 무작위로 Pod를 선택하여 라우팅 |
Temperature Policy 활성화 시 임계값 설정이 나타납니다:
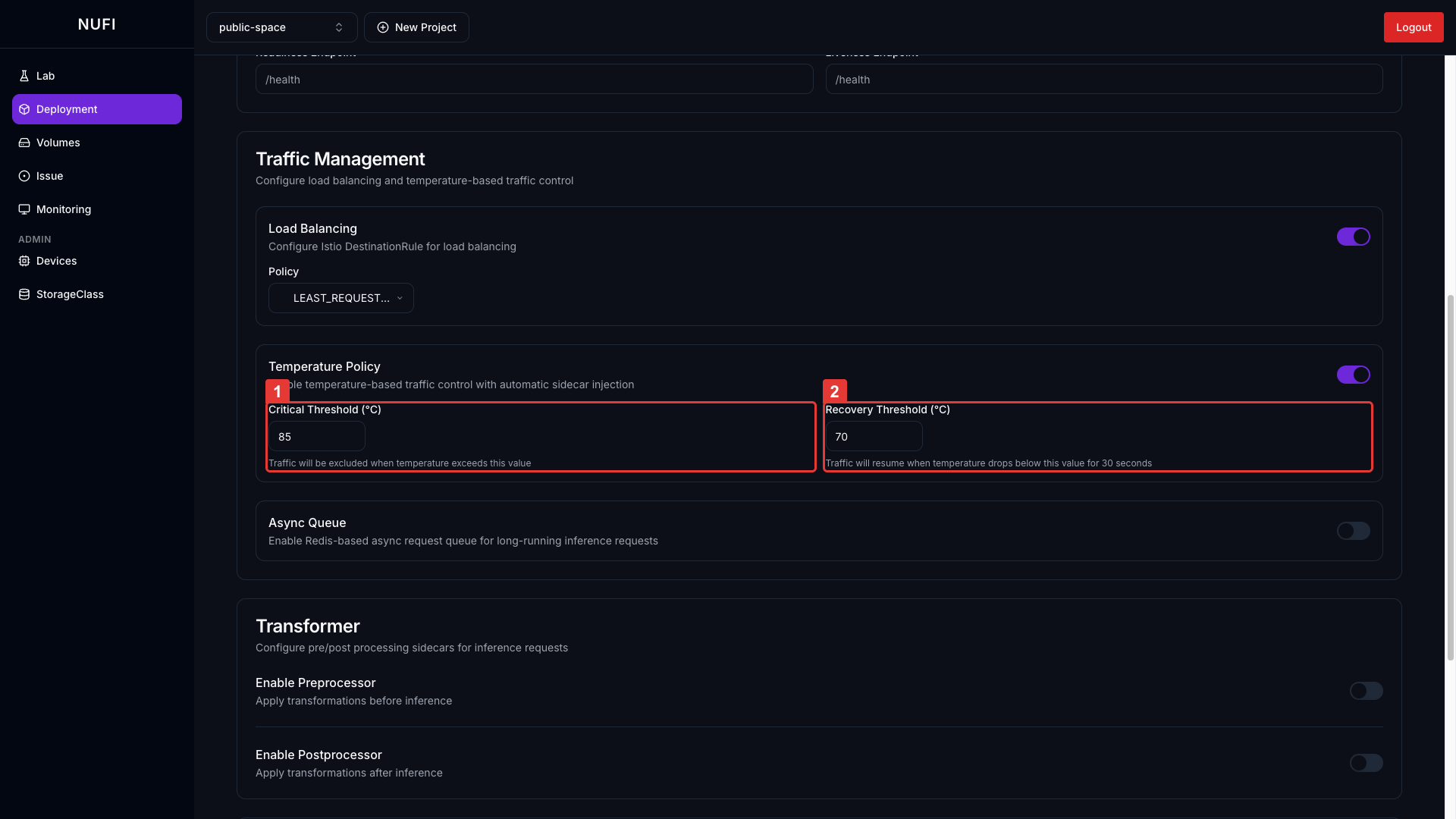
| 설정 | 설명 | 기본값 |
|---|---|---|
| Critical Threshold (°C) | 트래픽 차단 온도 기준 | 85 |
| Recovery Threshold (°C) | 트래픽 재개 온도 기준 | 70 |
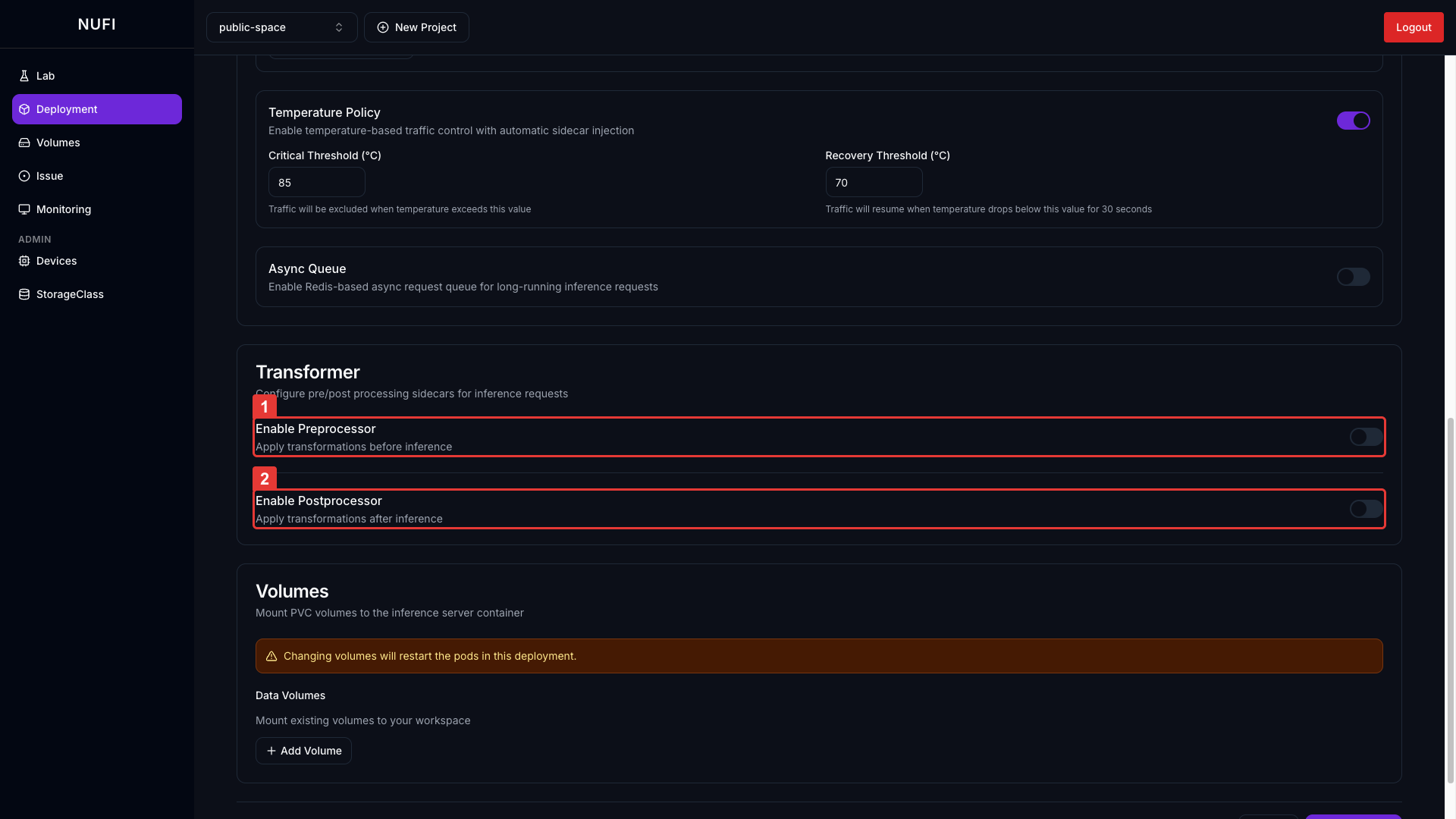
추론 요청 전/후에 사이드카 컨테이너를 거치도록 설정합니다.
| 기능 | 설명 |
|---|---|
| Enable Preprocessor | 요청 → 전처리 사이드카 → 추론 서버 |
| Enable Postprocessor | 추론 서버 → 후처리 사이드카 → 클라이언트 |
Preprocessor / Postprocessor 활성화 시 컨테이너 설정:
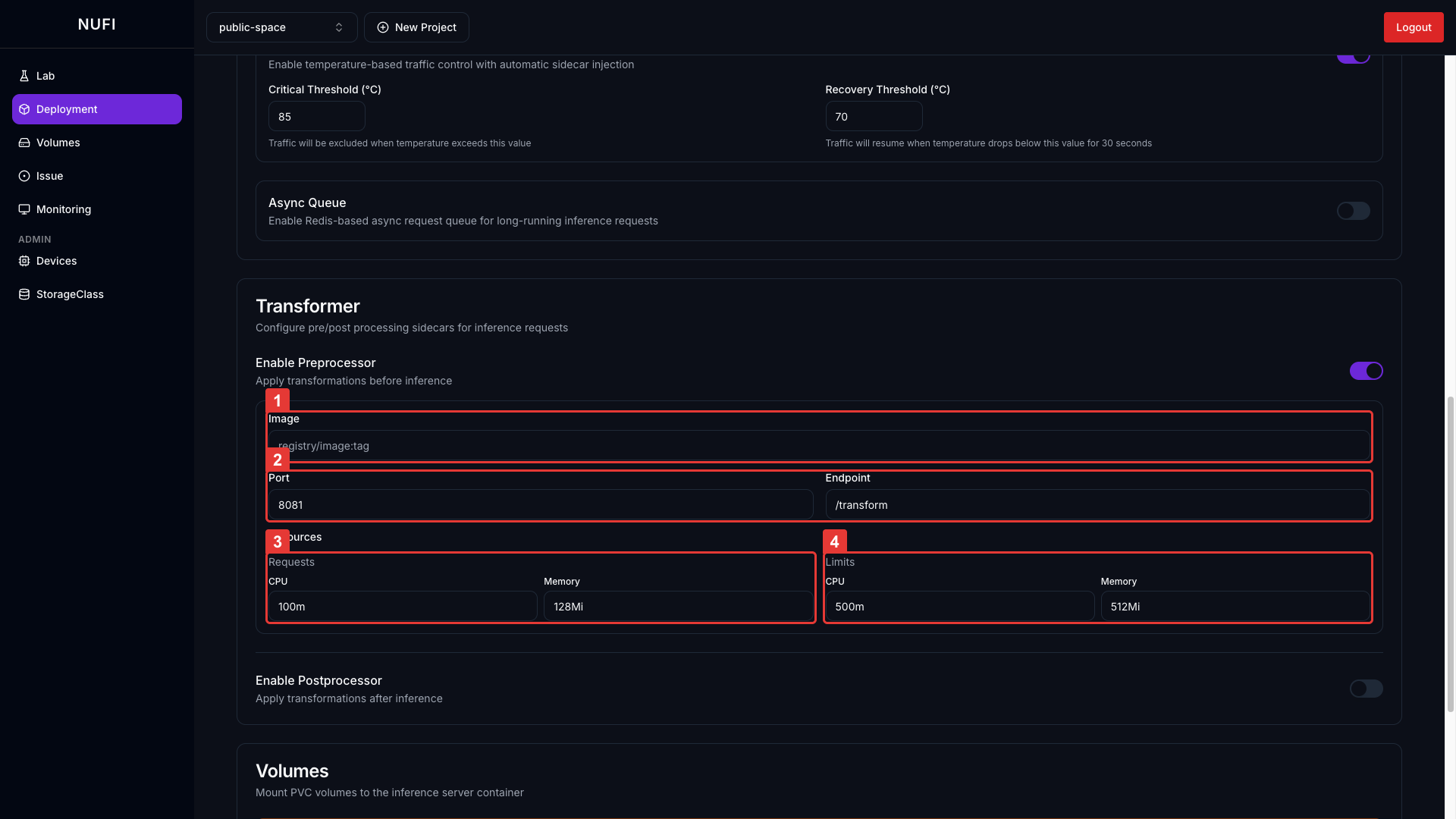
| 필드 | 설명 | 기본값 |
|---|---|---|
| Image | 전/후처리 컨테이너 이미지 | - |
| Port / Endpoint | 수신 포트 (Pre/Post는 포트가 달라야 함) | Pre: 8081, Post: 8082 |
| Requests | 최소 보장 리소스 | CPU: 100m, Memory: 128Mi |
| Limits | 최대 허용 리소스 | CPU: 500m, Memory: 512Mi |