Serving
AI 모델을 NPU/GPU 기반 추론 서비스로 배포하고 관리하는 방법을 안내합니다.
Serving 목록
좌측 사이드바에서 Development > Serving을 클릭합니다.
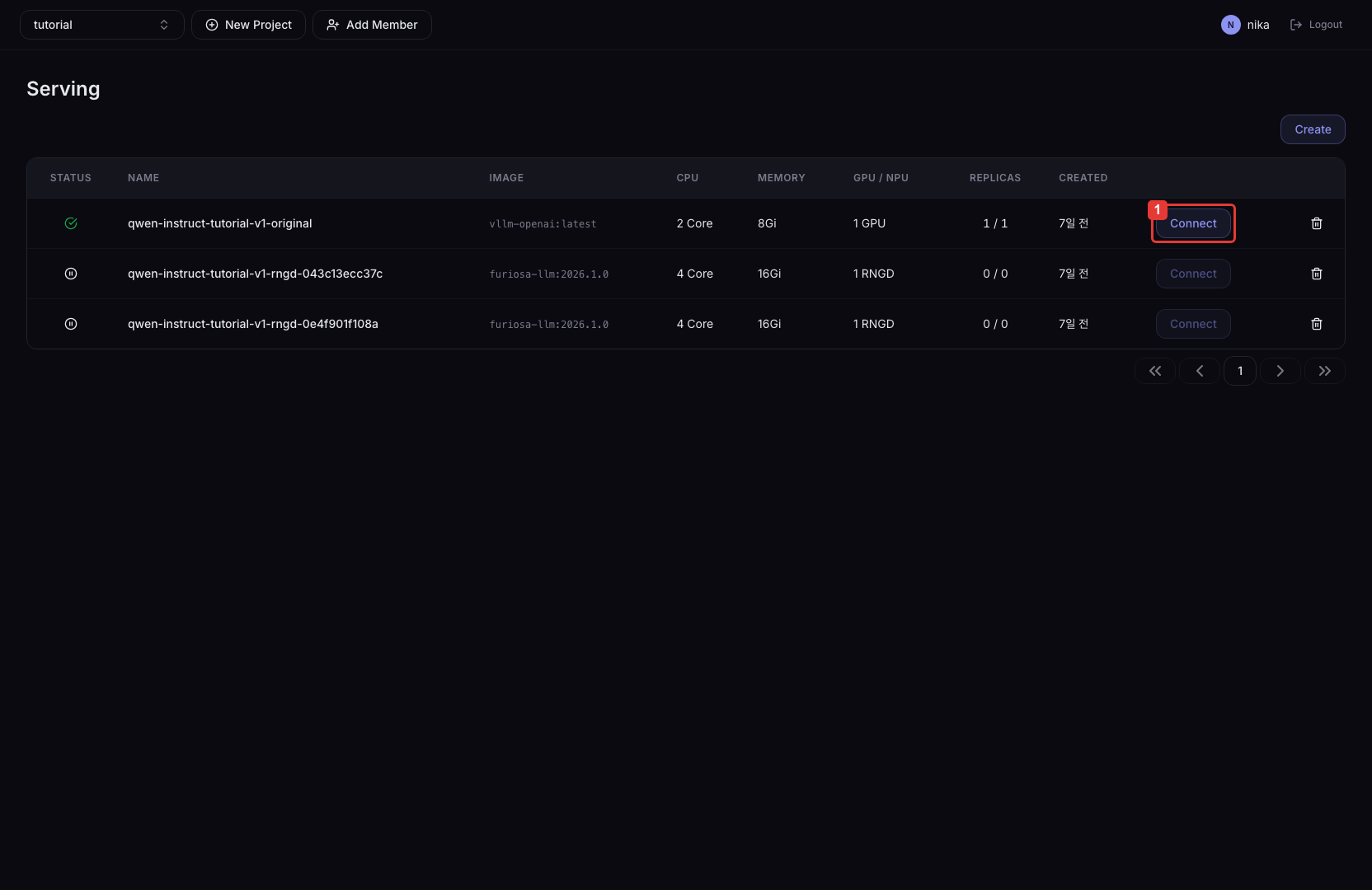
Connect 버튼을 클릭하면 배포한 서비스에 접속하기 위한 엔드포인트 URL을 확인할 수 있습니다. https://<host>/<project>/<deployment-name> 형식의 추론 엔드포인트 URL이 표시되며, 이 URL에 추론 프레임워크의 API 경로(예: /v1/chat/completions)를 붙여 외부에서 모델 추론 요청을 보낼 수 있습니다.
상태
| 상태 | 설명 | 비정상 대응 |
|---|---|---|
| Ready | 모든 Pod이 Ready 상태. 서비스 정상 운영 중 | — |
| Starting | Pod이 시작 중. 모델 로딩 등으로 아직 Ready가 아닌 상태 | 잠시 대기하세요. 오래 지속되면 로그를 확인하세요. |
| Degraded | 일부 Pod만 Ready. 요청은 처리되지만 전체 성능이 저하됨 | 실패 Pod의 로그 및 이벤트를 확인하세요. |
| Error | 하나 이상의 Pod이 CrashLoopBackOff 등 오류 상태 | Status 컬럼 클릭 → popover에서 failureReason 및 로그 확인 |
| Pending | Pod이 스케줄되지 않음. 리소스 부족 또는 이미지 Pull 실패 | 클러스터 리소스 현황 및 이미지 설정을 확인하세요. |
| Scaled Down | Replica가 0으로 축소된 상태 | 필요 시 Replicas를 1 이상으로 변경하세요. |
Status 컬럼 hover 또는 클릭 시 Pod 상태 popover가 표시됩니다. popover에는 주 에러 reason, Ready 카운트, 실패 Pod 목록과 각 Pod의 View logs 링크(새 탭, Logs 탭으로 이동)가 포함됩니다.
Serving 생성
Create 버튼을 눌러 생성 페이지로 이동합니다. 생성은 3단계로 진행됩니다.
- Step 1. 기본 정보
- Step 2. 상세 설정
- Step 3. 리뷰 & 배포
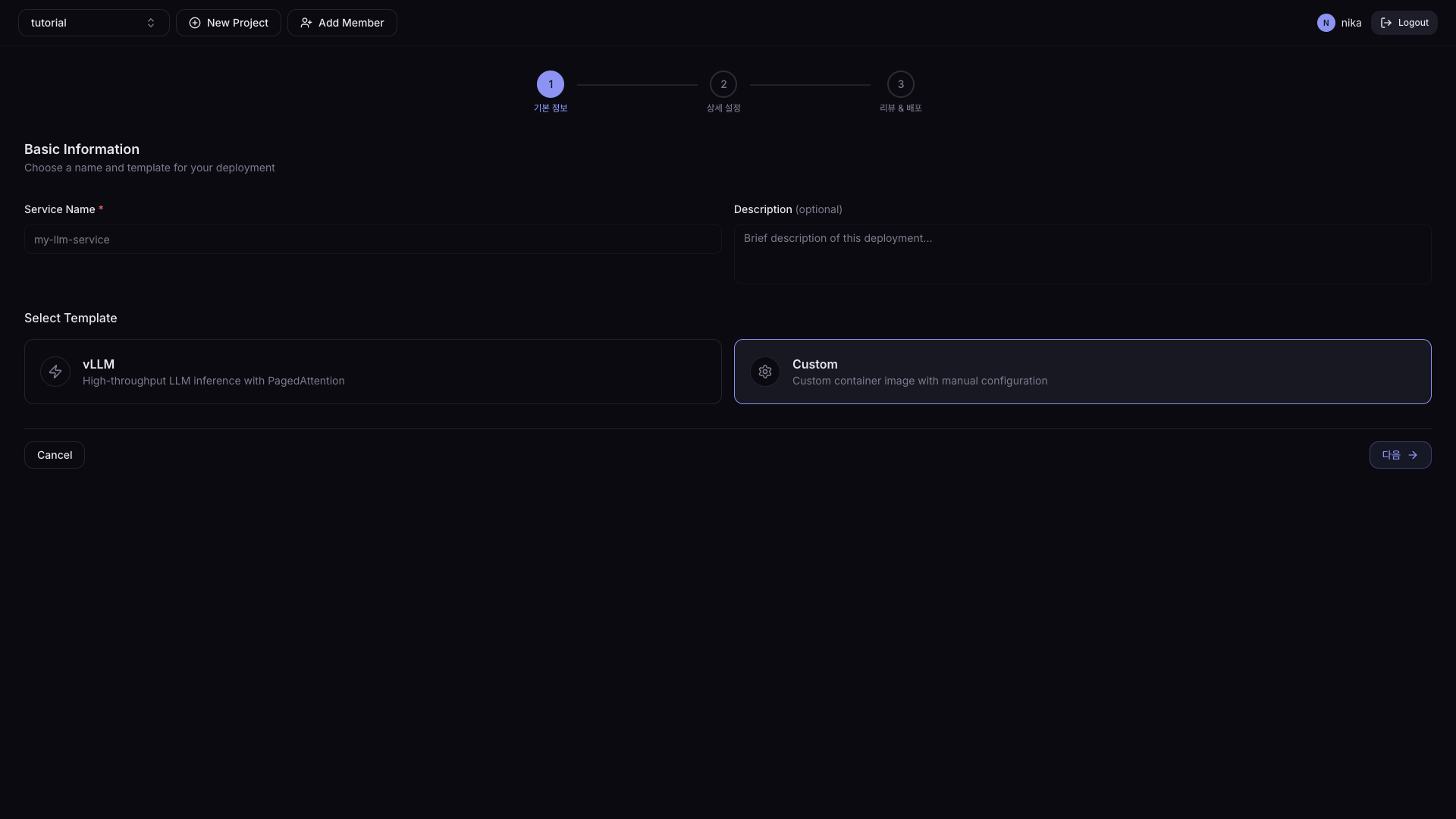
| 필드 | 설명 | 필수 |
|---|---|---|
| Service Name | Serving 이름 (소문자, 숫자, 하이픈, 최대 63자) | ✓ |
| Description | Serving 설명 | - |
| Service Template | 추론 프레임워크 선택 | ✓ |
공통 설정:
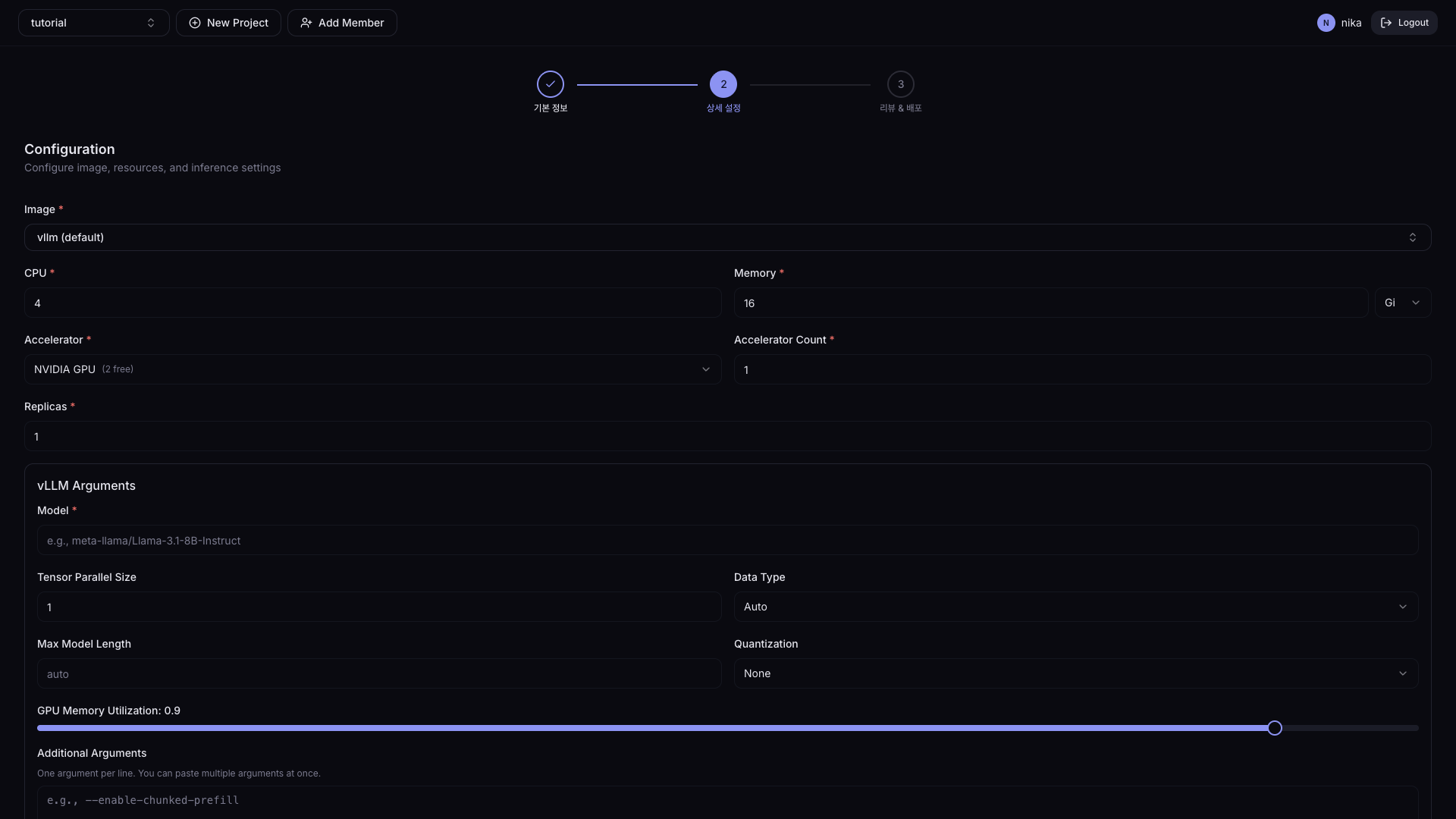
| 필드 | 설명 | 기본값 |
|---|---|---|
| Image | 컨테이너 이미지 | - |
| CPU | CPU 코어 수 | 0.5 |
| Memory | 메모리 | 1Gi |
| Accelerator | 가속기 유형 | None |
| Accelerator Count | 가속기 개수 | 1 |
| Replicas | 서비스 컨테이너 개수 | 1 |
템플릿별 추가 설정:
- vLLM
- Custom
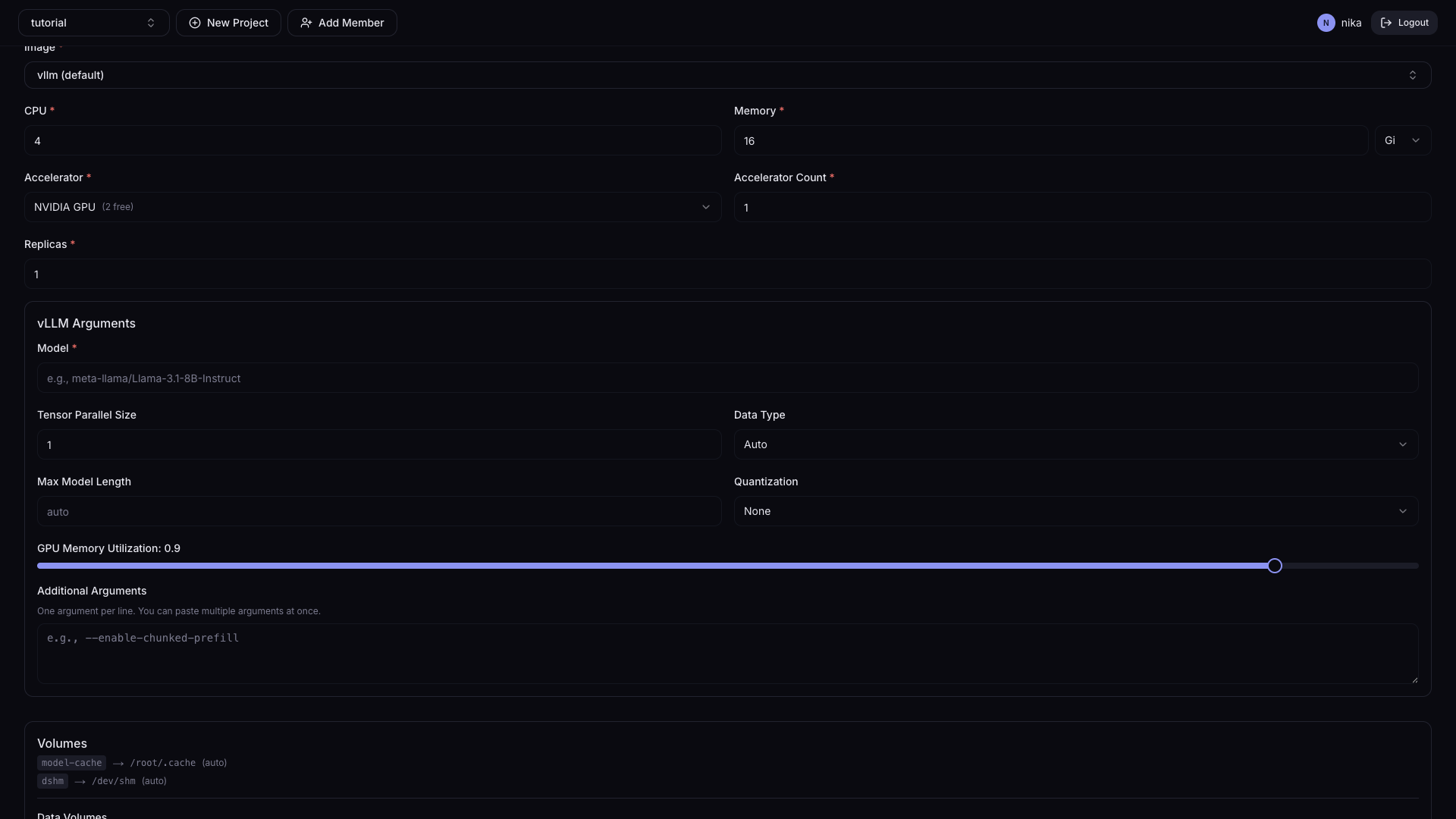
| 필드 | 설명 | 기본값 |
|---|---|---|
| Model | 모델 이름 또는 경로 (예: meta-llama/Llama-3.1-8B-Instruct) | - |
| Tensor Parallel Size | 모델을 나눠 올릴 GPU 수 | 1 |
| Data Type | 모델 연산 숫자 표현 방식 | Auto |
| Max Model Length | 최대 처리 토큰 수 (입력+출력 합산) | - |
| Quantization | 모델 정밀도 낮춰 메모리 절약 | - |
| GPU Memory Utilization | vLLM이 사용할 GPU 메모리 비율 (0.0~1.0) | 0.9 |
| Additional Arguments | vLLM 고급 설정 직접 입력 | - |
Custom 템플릿은 공통 설정(Image, CPU, Memory, Accelerator, Replicas)과 Advanced Settings만 사용합니다. 컨테이너 이미지와 Command Override로 직접 제어합니다.
Data Volumes (선택):
마운트할 PVC를 추가합니다. 하드코딩 볼륨(model-cache, dshm)은 시스템 기본 볼륨으로 읽기 전용으로 표시되며, 사용자가 생성한 PVC를 추가로 지정할 수 있습니다.
+ Add Volume 버튼으로 사용자 PVC를 추가 마운트할 수 있습니다.
Advanced Settings (선택):
| 필드 | 설명 | 기본값 |
|---|---|---|
| Inference Port | 서비스 추론 포트 | 8000 |
| Command Override | 컨테이너 시작 명령어 | - |
| Environment Variables | 환경변수 (KEY=VALUE 또는 env file) | - |
| Transformer | 전/후처리 사이드카 추가 | - |
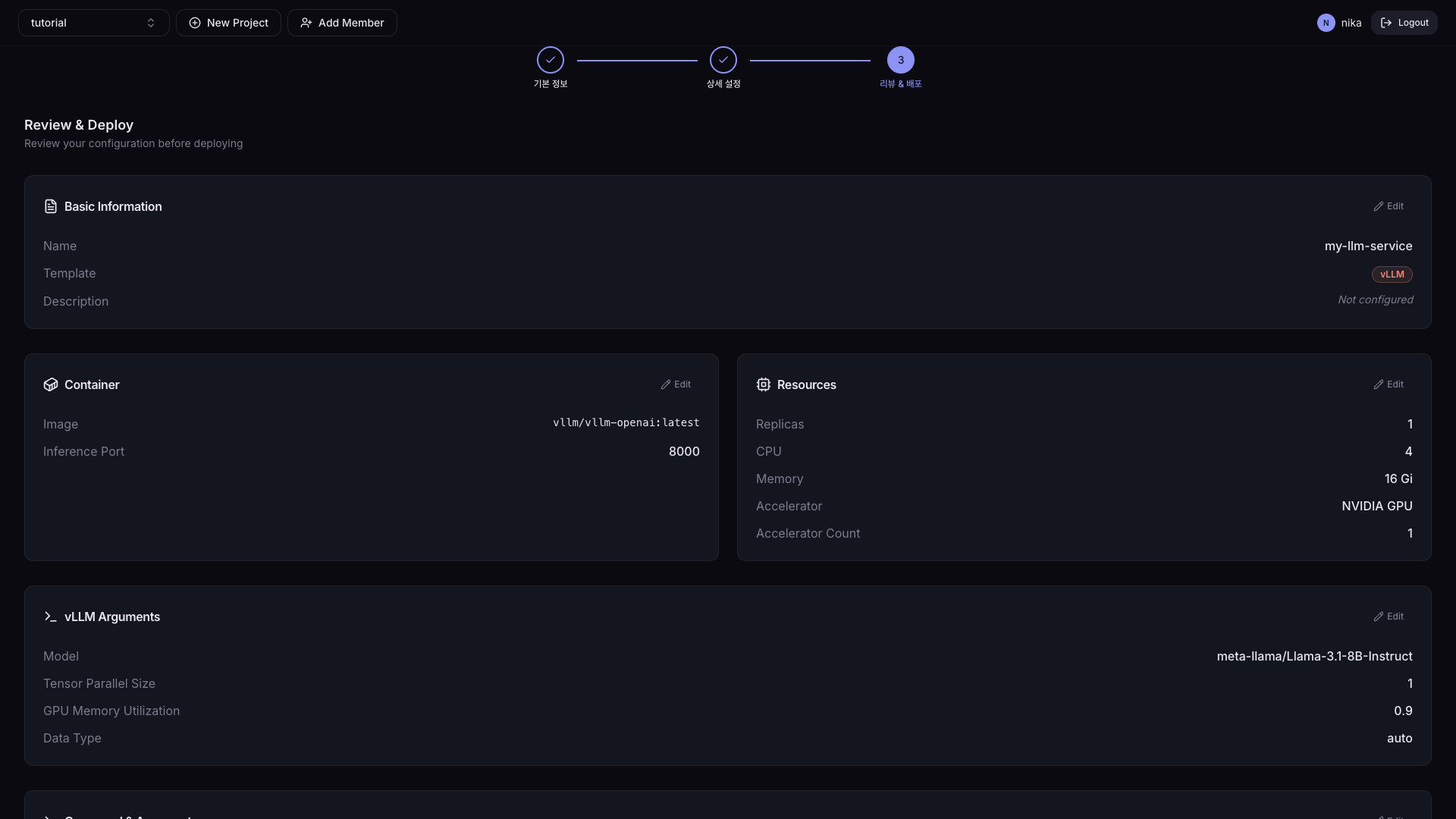
수정할 스펙이 있으면 Edit 버튼으로 수정합니다. 우측 하단 배포 버튼을 클릭하여 배포합니다.
Serving 상세 페이지
Serving 목록에서 항목을 클릭하면 상세 페이지로 이동합니다. Overview 탭 우측 상단의 Edit 버튼을 클릭하면 편집 모드로 전환되며, 변경 후 화면 하단의 Floating Save Bar에서 Save Changes 버튼을 클릭하여 적용합니다. Pod 재시작이 필요한 변경(이미지, 포트, 리소스, 볼륨 등)이 포함된 경우 확인 다이얼로그가 표시됩니다.
- Overview
- Metrics
- Logs
- Async Queue
- Settings
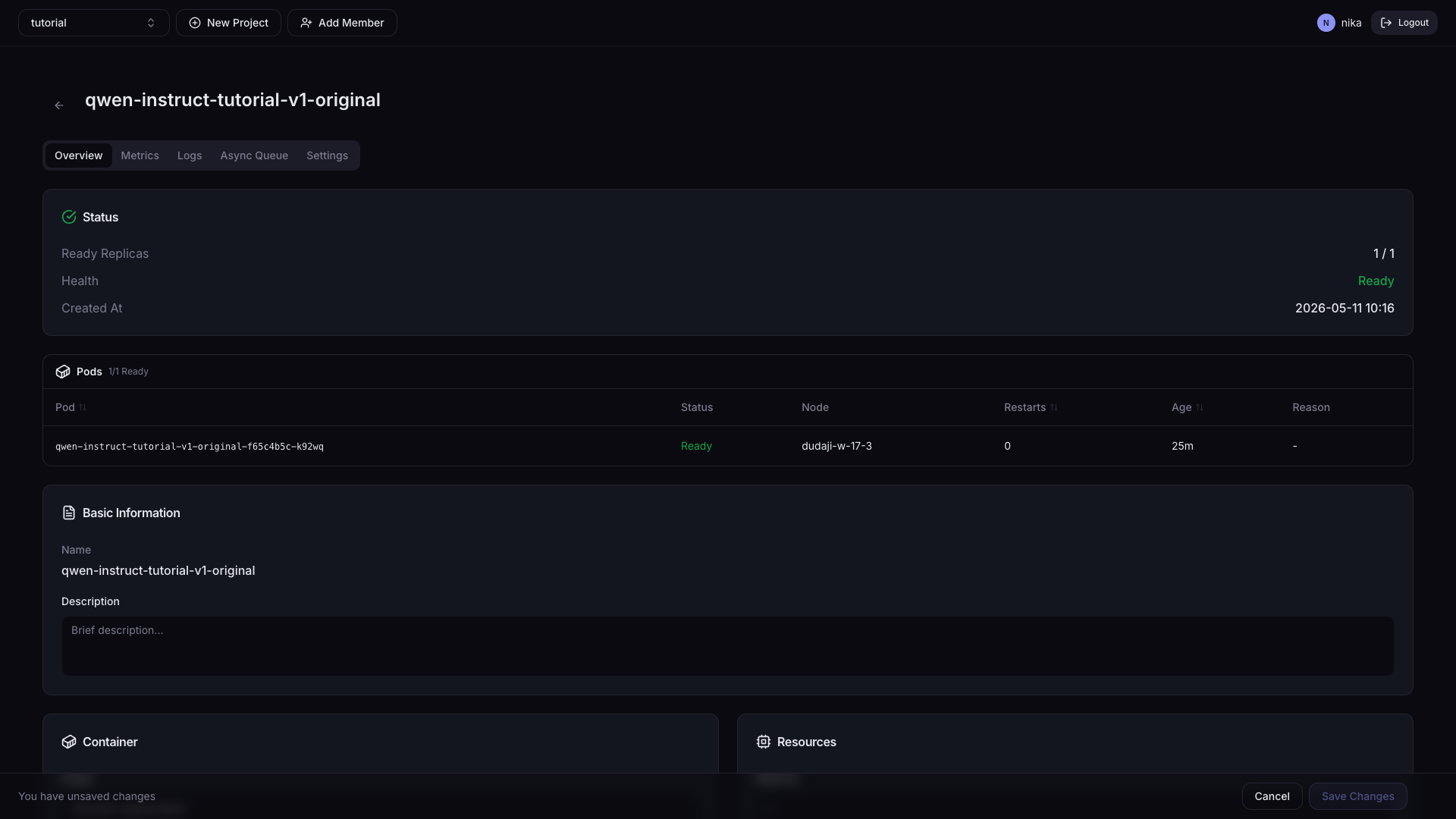
카드 구성
| 카드 | 설명 |
|---|---|
| Status | Ready Replicas, Health, Auto Scaling, 생성 시각 |
| Basic Information | Serving 이름, 설명 |
| Container | 컨테이너 이미지, 추론 포트 |
| Resources | CPU, Memory, 가속기 유형/개수, Replicas |
| Command & Arguments | 컨테이너 시작 명령어 및 인자 |
| Environment Variables | 환경변수 목록 |
| Volumes | 마운트된 PVC 목록 |
| Transformer | 전/후처리 사이드카 설정 |
| Pods | Pod별 상태 테이블 — 실패 Pod 우선 정렬 |
Pods 섹션
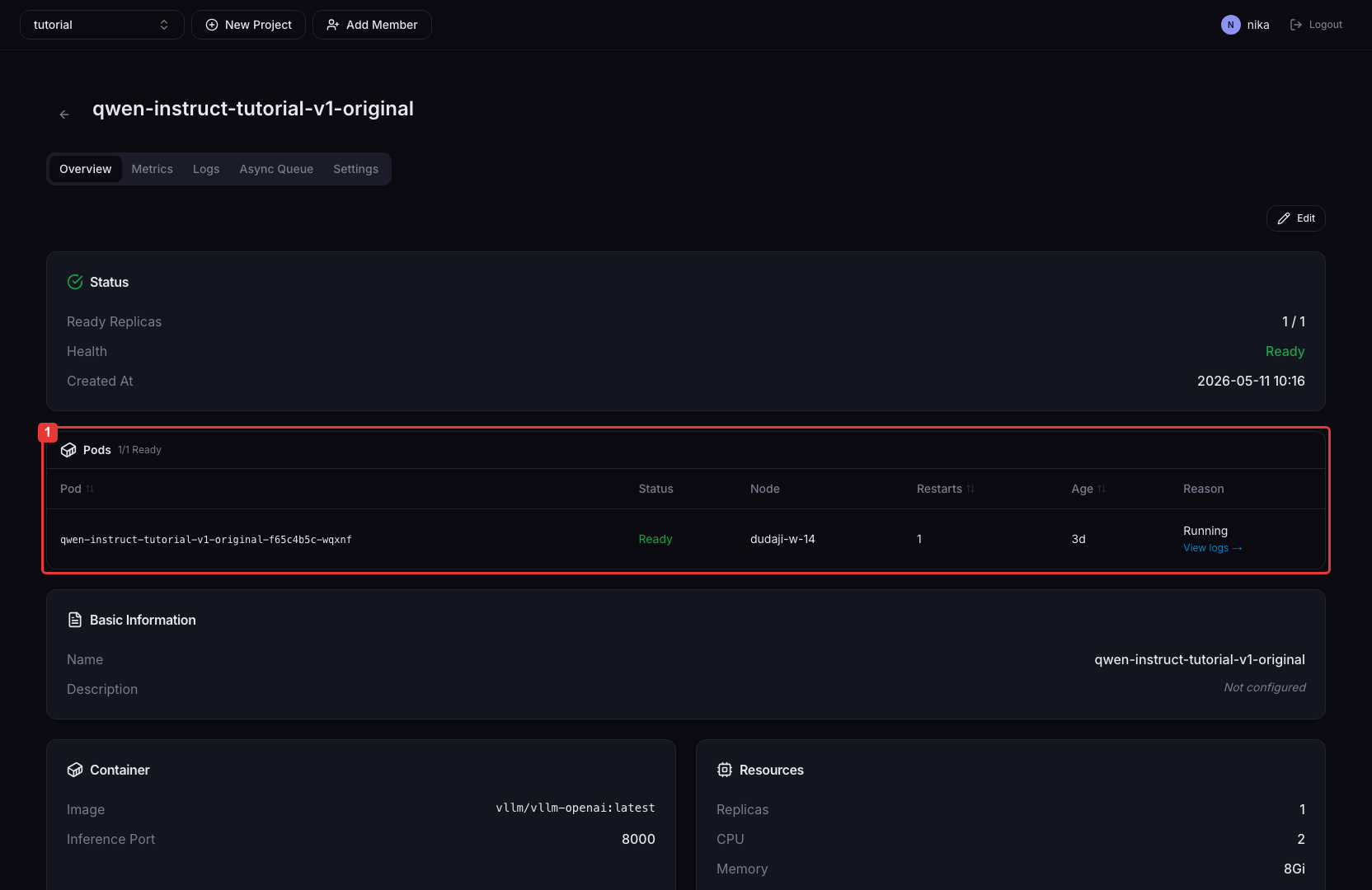
Pod별 상태, 노드, 재시작 횟수, Age, 실패 이유를 테이블로 표시합니다.
| 컬럼 | 설명 |
|---|---|
| Status | Pod의 현재 상태 (Running / Pending / CrashLoopBackOff 등) |
| Node | Pod이 스케줄된 노드 이름 |
| Restarts | 컨테이너 재시작 횟수 |
| Age | Pod 생성 후 경과 시간 |
| Reason | Ready=false 또는 오류 시 실패 원인 메시지 |
| View logs | Ready=false이거나 restartCount > 0인 Pod에 표시되는 로그 링크. 클릭 시 새 탭에서 해당 Pod의 Logs 탭으로 이동 |
실패 Pod은 테이블 상단에 우선 정렬됩니다.
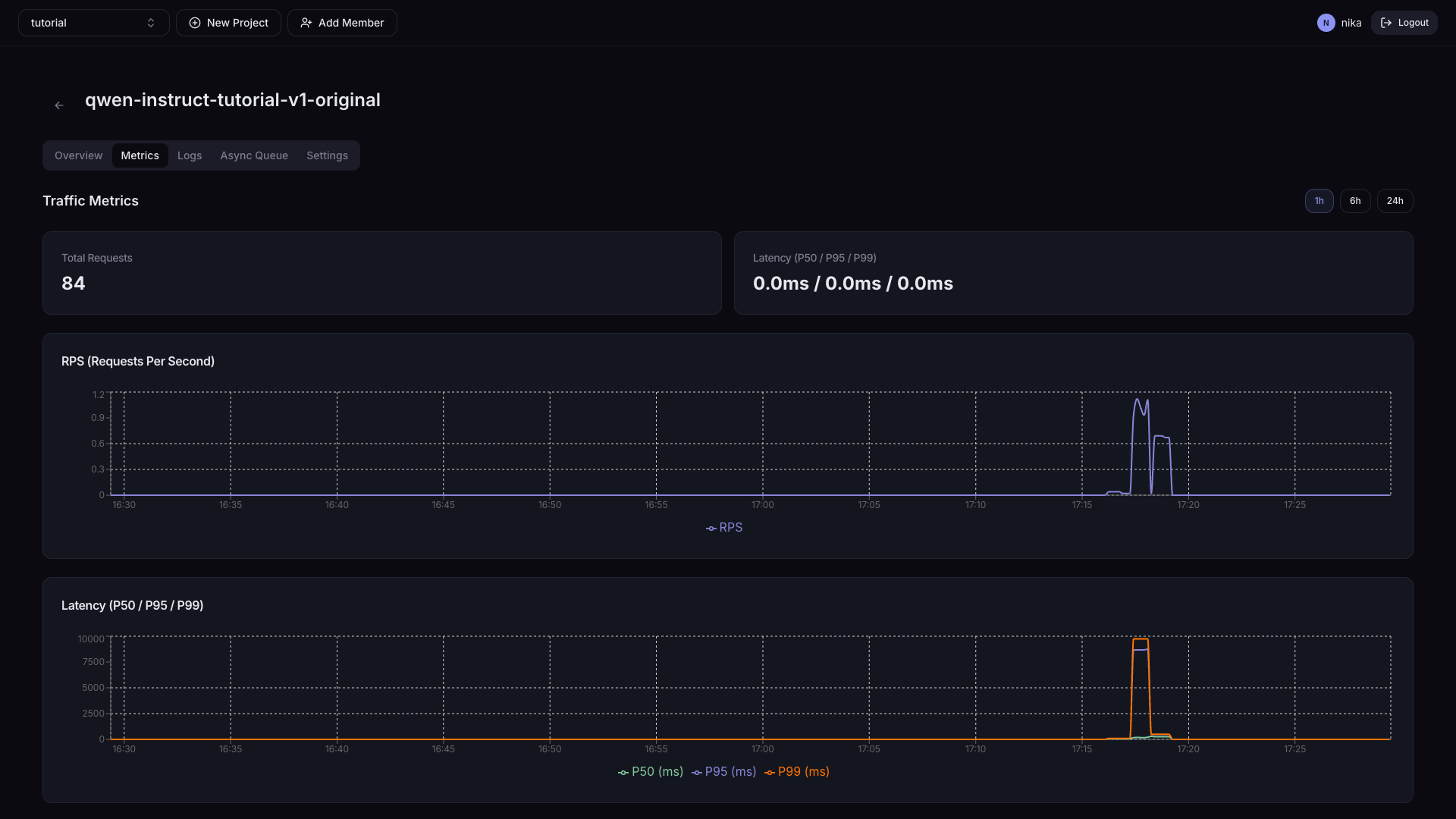
우측 상단 시간 범위 버튼(1h / 6h / 24h)으로 그래프 기간을 조절할 수 있습니다.
| 카드 | 정보 |
|---|---|
| Total Requests | 전체 요청 횟수 |
| Latency (P50 / P95 / P99) | 현재 요청 응답 시간 |
| RPS 그래프 | 초당 요청 개수 시계열 |
| Latency 그래프 | P50/P95/P99 응답 시간 시계열 |
추론 서버 컨테이너의 실행 로그를 출력합니다.
Settings에서 Async Queue를 활성화하면 비동기 요청 목록과 처리 결과를 조회합니다.
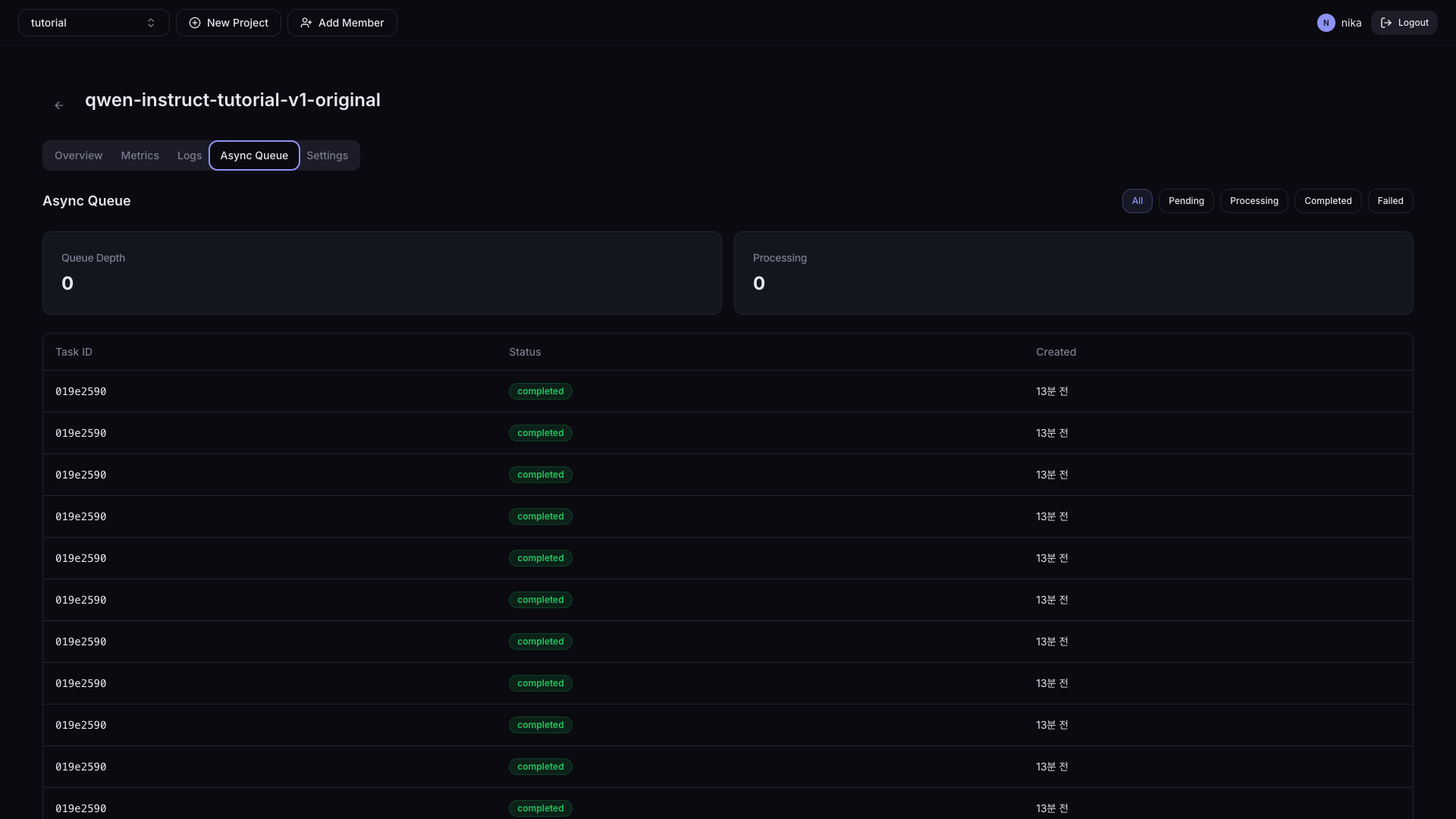
| 항목 | 설명 |
|---|---|
| 상태 필터 | All / Pending / Processing / Completed / Failed |
| Queue Depth | 현재 Queue에 쌓인 Task 수 |
| Processing | 현재 진행 중인 Task 수 |
특정 Task를 클릭하면 Request / Response 상세 정보를 확인할 수 있습니다.
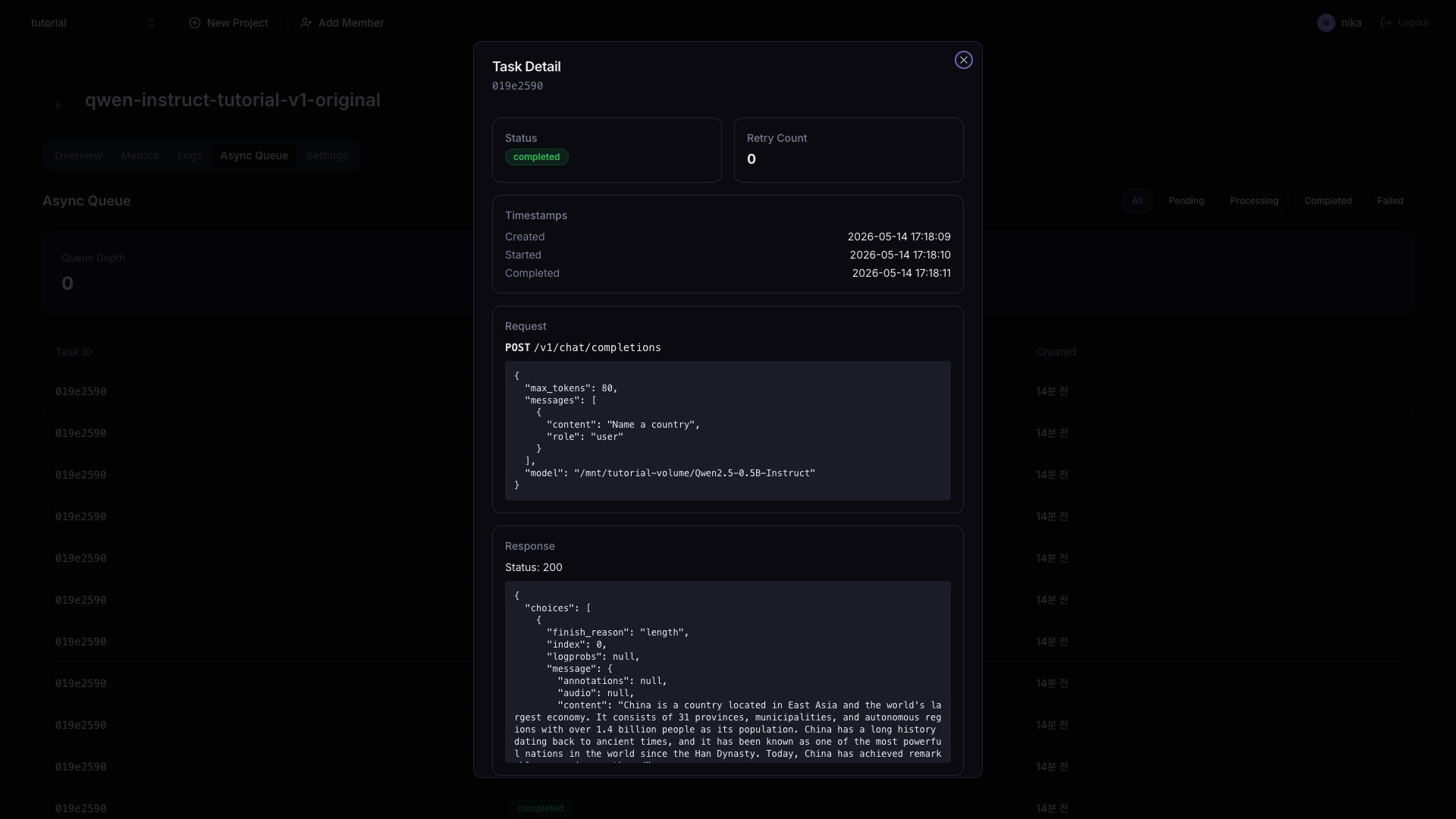
비동기 요청 방법 — HTTP 요청 시 X-Async: true 헤더를 추가합니다.
curl -X POST 'https://<deployment-endpoint>/v1/chat/completions' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer <token>' \
-H 'X-Async: true' \
-d '{"model": "모델명", "messages": [{"role": "user", "content": "안녕하세요"}]}'
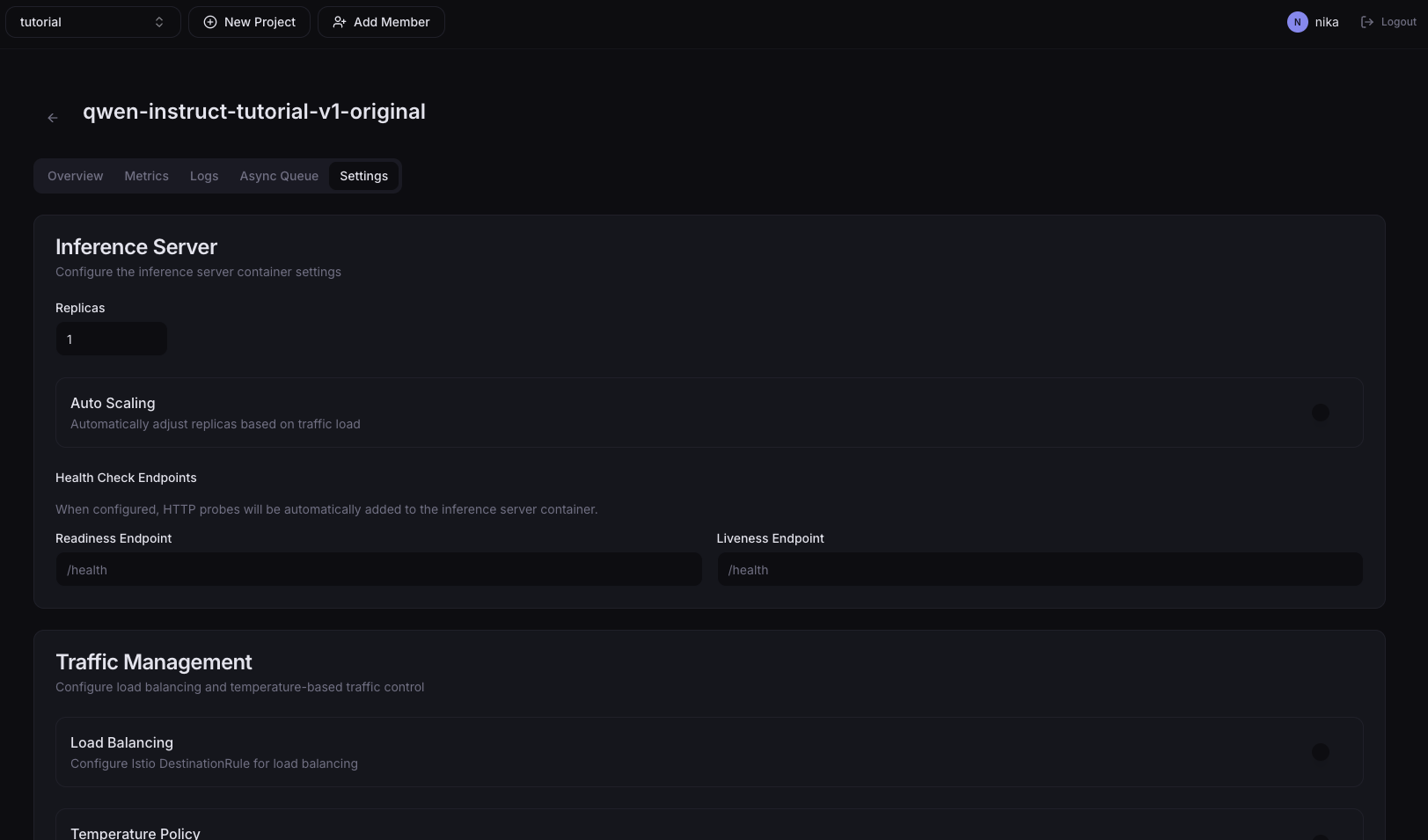
추론 서버 스케일링, 헬스 체크, 트래픽 분배, 비동기 큐 등 Serving 운영에 필요한 설정을 변경합니다. 항목별 상세 설명은 배포 고급 설정을 참고하세요.
네이밍 규칙
- 소문자 영문, 숫자, 하이픈(-) 사용 가능
- 하이픈으로 시작하거나 끝날 수 없음
- 최대 63자 (Kubernetes 제한)
예시: my-model-v1, llm-server-prod
지원 가속기
| 가속기 | 리소스 키 | 사용 가능 기능 |
|---|---|---|
| NVIDIA GPU | nvidia.com/gpu | Lab, Serving |
| Furiosa RNGD | furiosa.ai/rngd | Lab, Serving |