Monitoring
클러스터 전체 리소스 현황과 GPU/NPU 디바이스 상태를 확인하는 방법을 안내합니다.
좌측 사이드바에서 Monitoring 메뉴를 클릭하면 시스템 모니터링 정보가 표시됩니다.
Cluster Overview
클러스터 전반의 평균 리소스 사용량을 카드와 시계열 그래프로 표시합니다.
우측 상단의 시간 버튼(1h / 6h / 24h / 7d)으로 시계열 그래프 범위를 조절할 수 있습니다.
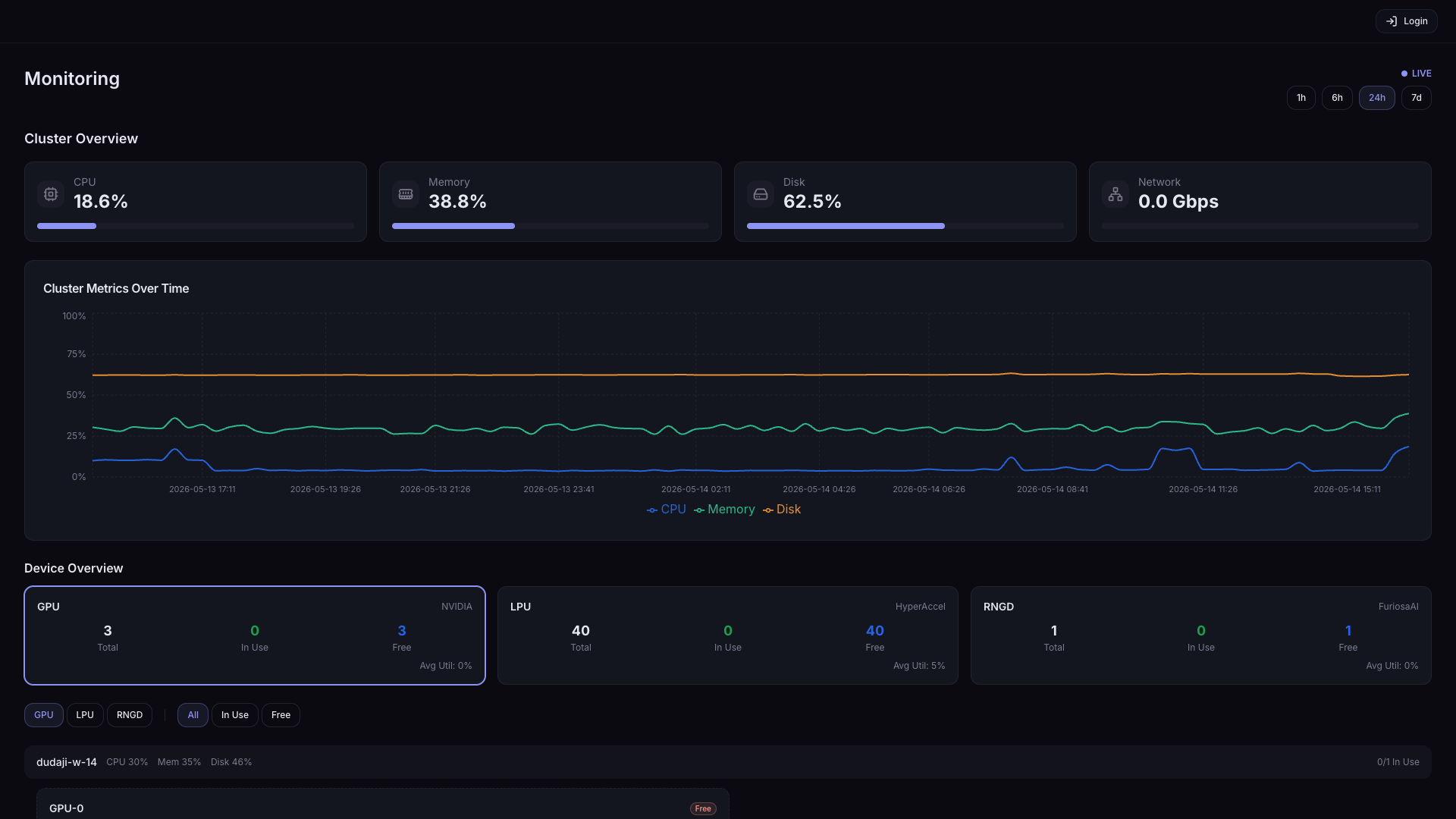
| 카드 | 설명 |
|---|---|
| CPU | 클러스터 노드 평균 CPU 사용률 |
| Memory | 클러스터 노드 평균 메모리 사용률 |
| Disk | 클러스터 노드 디스크 사용률 |
| 시계열 그래프 | 위 정보들에 대한 시계열 그래프 |
Device Overview
GPU/NPU 가속기 현황을 표시합니다.
| 항목 | 설명 |
|---|---|
| 가속기 종류별 Overview | 전체 / 할당 / 미할당 개수 및 평균 사용률 |
| 가속기 종류 필터 | 가속기 종류별 필터 |
| 가속기 할당 상태 필터 | 가속기 할당 상태에 따른 필터 |
| 노드 카드 | 노드별 CPU / Memory / Disk 사용률 및 설치된 가속기 정보 |
| 디바이스 카드 | 개별 디바이스의 Usage / Temp / Power / VRAM 사용률, 할당된 Pod 정보 |
팁
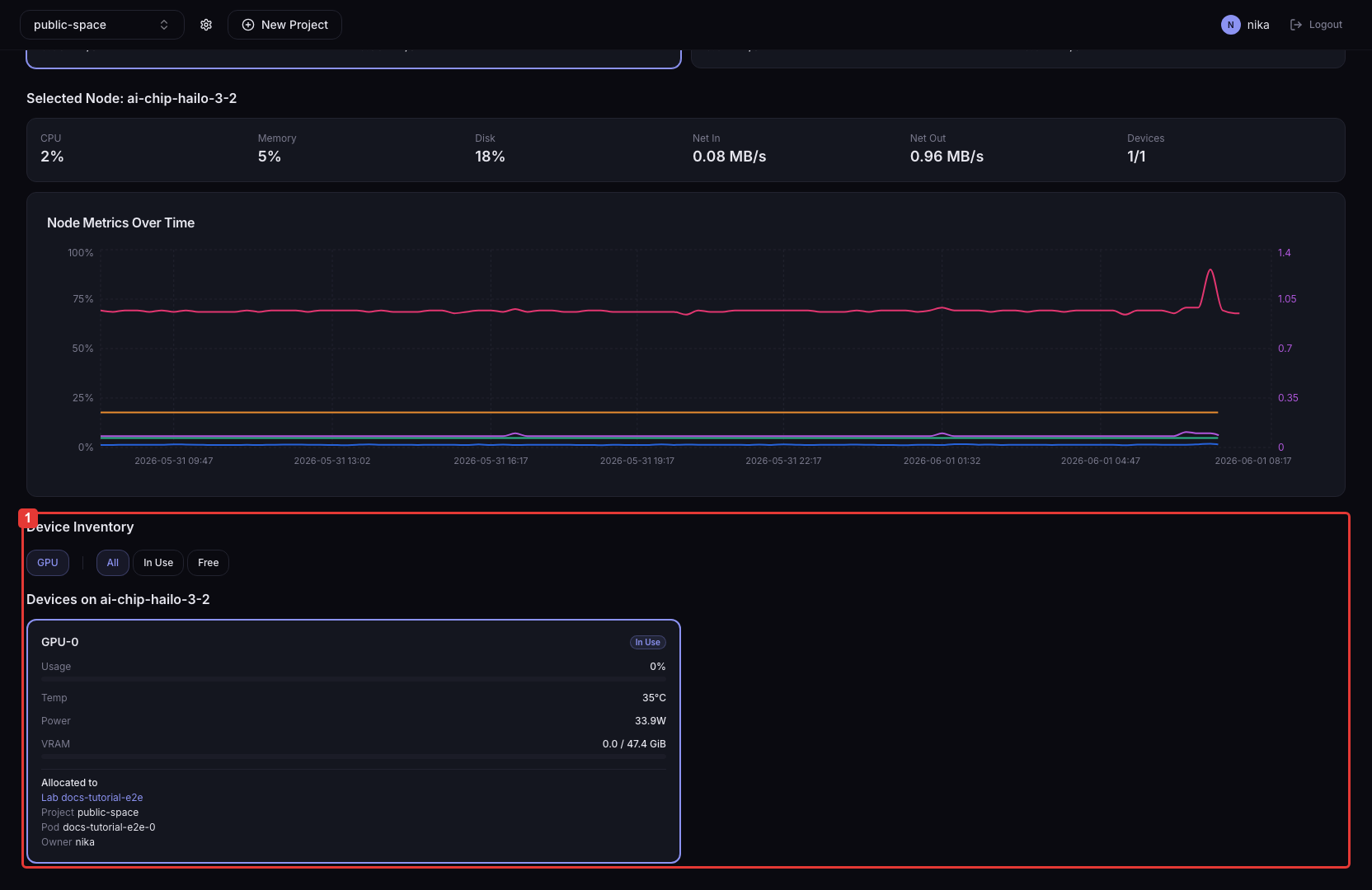
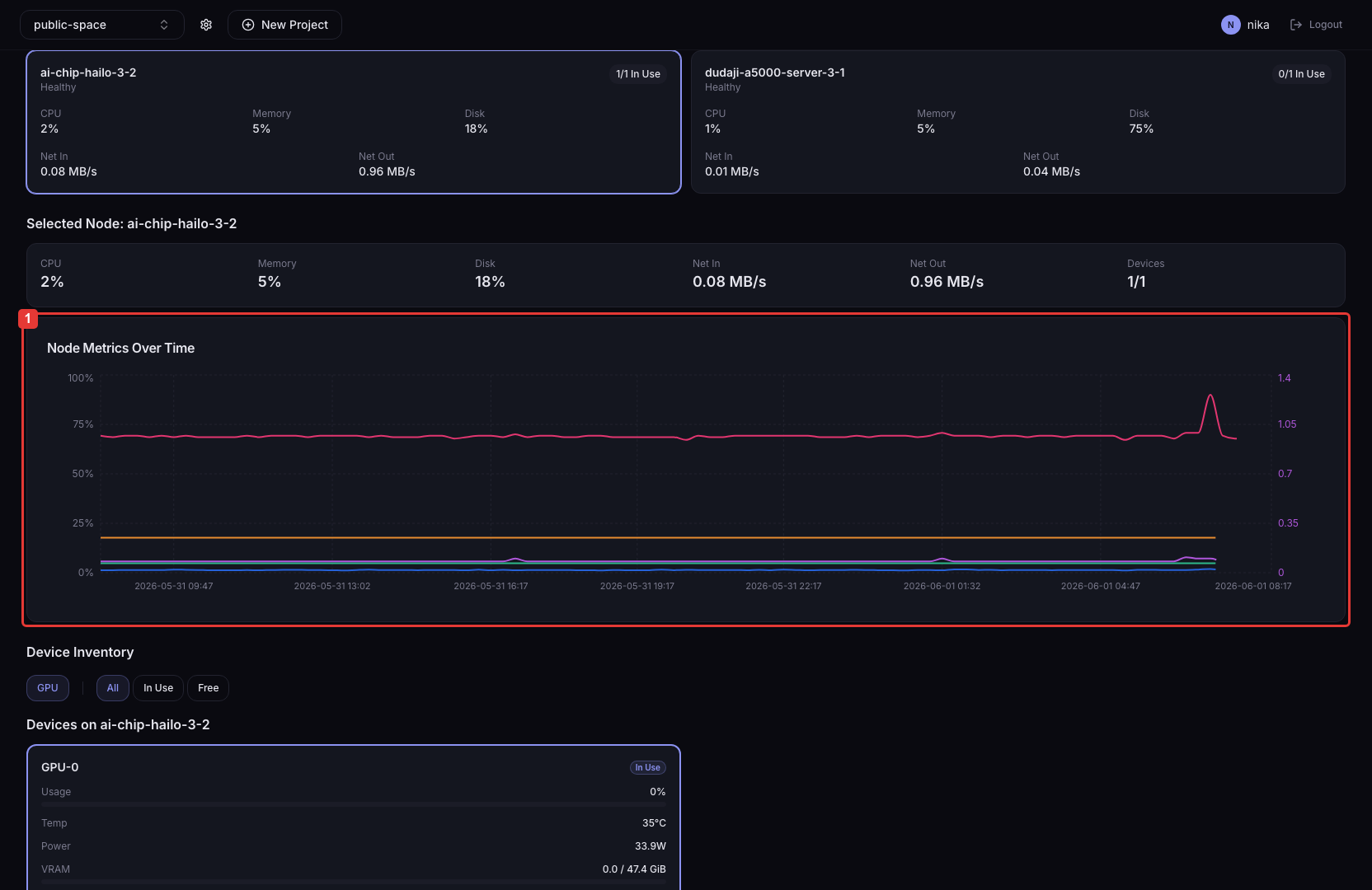
노드 카드 또는 디바이스 카드를 클릭하면 해당 항목의 시계열 그래프를 확인할 수 있습니다.
- 노드 카드 클릭
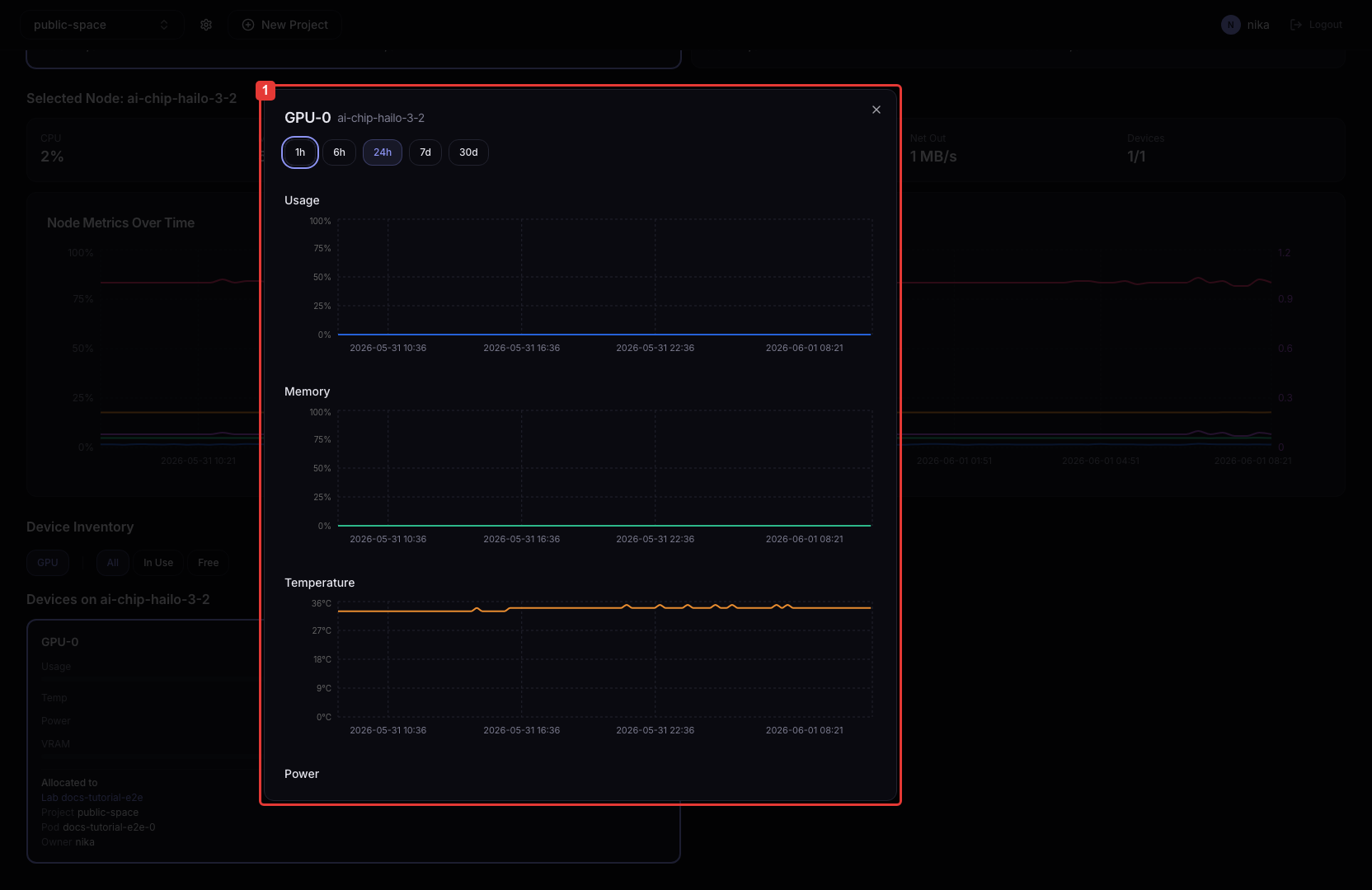
- 디바이스 카드 클릭
해당 노드의 CPU / Memory / Disk 시계열 그래프가 표시됩니다.
해당 디바이스의 Usage / Memory / Temperature / Power 시계열 그래프가 표시됩니다.
이상 징후 대응
모니터링 중 다음 상황이 발생하면 아래 조치를 취하세요.
| 증상 | 조치 |
|---|---|
| 디바이스 온도 과열 | 배포 고급 설정의 Temperature Policy를 확인하고, 임계값 초과 시 자동 스케일다운 또는 트래픽 제한이 적용되는지 점검합니다. |
| 가속기 사용률 지속 100% | 모델 배포에서 Replica 수를 늘리거나 Auto Scaling 설정을 조정합니다. |
| 노드 메모리·디스크 부족 | 불필요한 Serving을 중지하거나, 스토리지에서 사용하지 않는 볼륨을 정리합니다. |