모델 서빙 배포
컴파일된 아티팩트를 사용하여 NPU 또는 GPU 기반 추론 서비스를 배포합니다.
NPU 서빙 배포
컴파일된 RNGD 아티팩트를 사용하여 NPU 기반 추론 서비스를 배포합니다.
1. 모델 선택
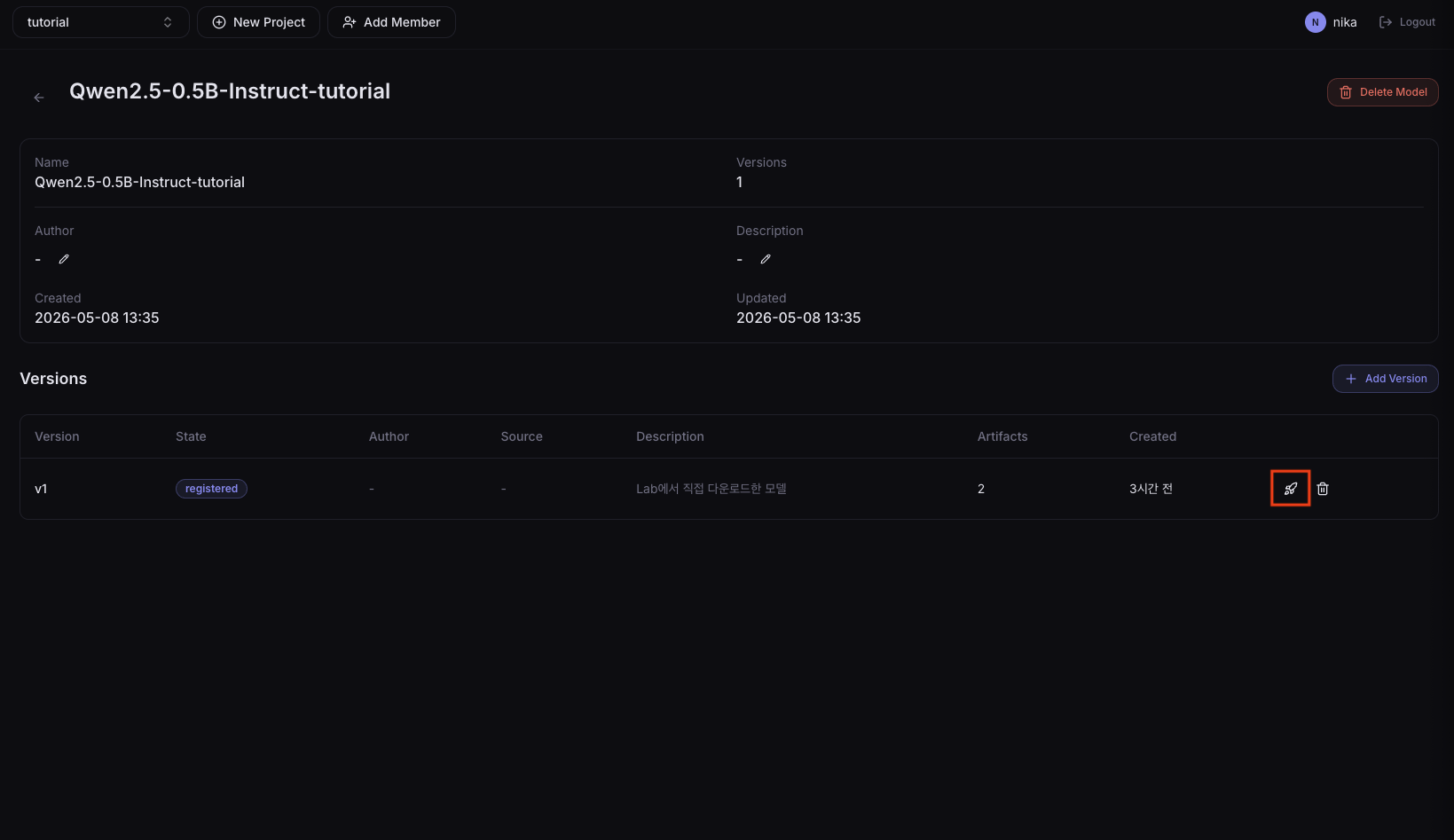
좌측 사이드바에서 Resources > Models를 클릭하고 03. 모델 다운로드에서 다운로드한 qwen-instruct-tutorial 모델을 선택합니다.
2. Quick Deploy
모델 상세 페이지에서 Quick Deploy 버튼을 클릭합니다.
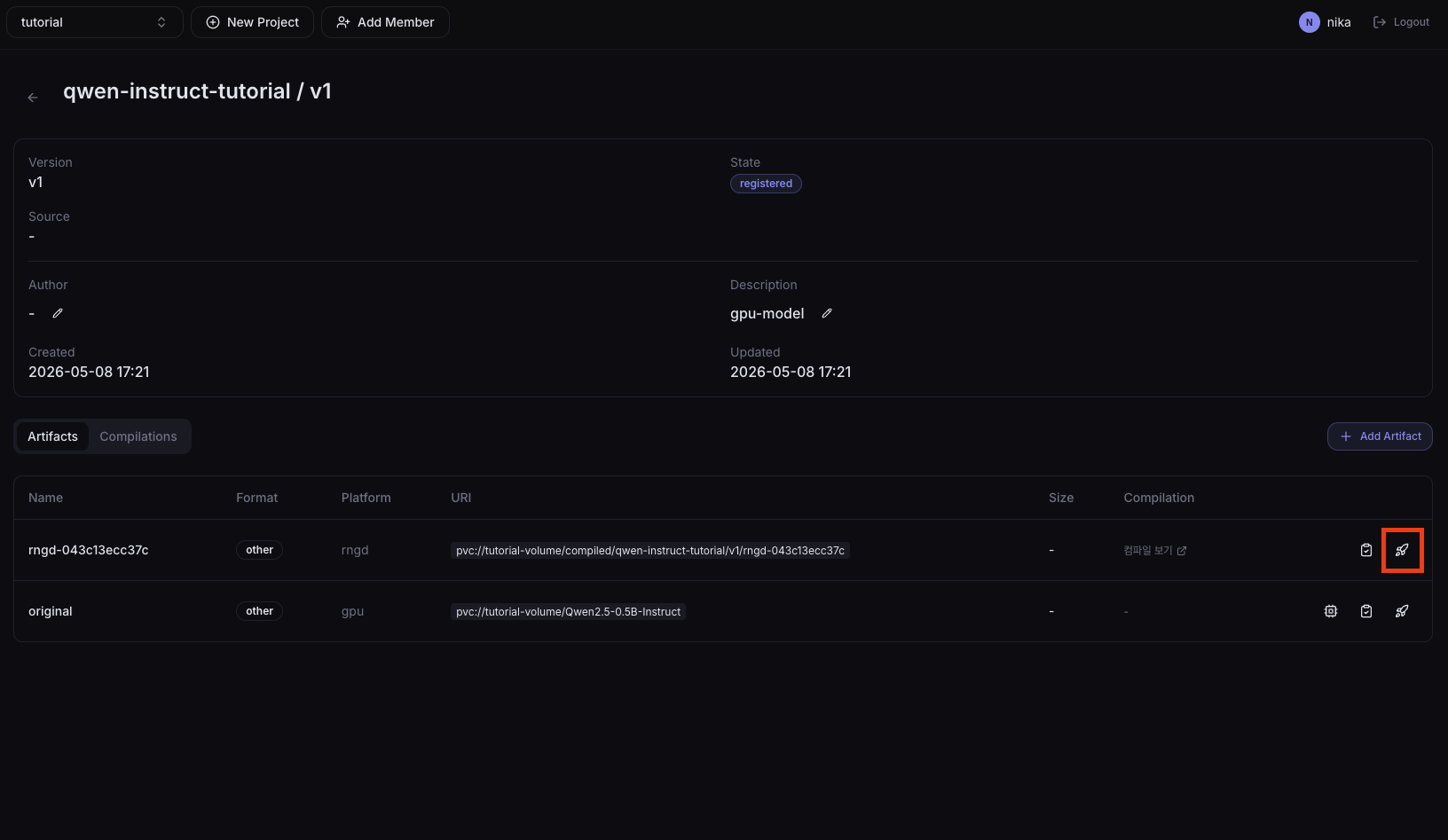
목록에 있는 버전을 클릭하여 상세 페이지로 들어가면 컴파일된 내역을 확인할 수 있으며, 해당 페이지에서도 배포가 가능합니다.
3. 배포 설정 입력
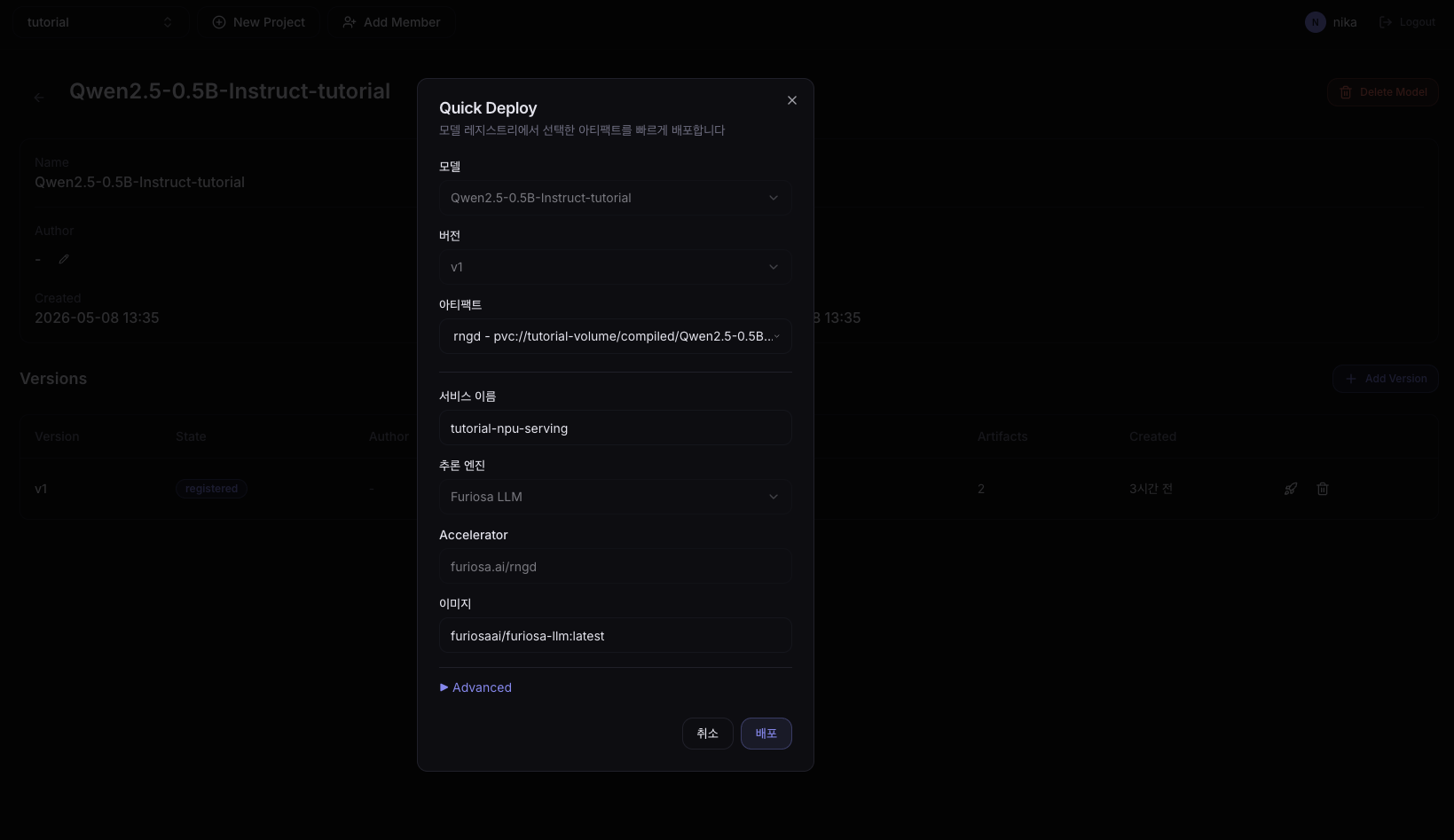
| 필드 | 예시 값 |
|---|---|
| Service Name | tutorial-npu-serving |
| Version | v1 |
| Artifact | rngd |
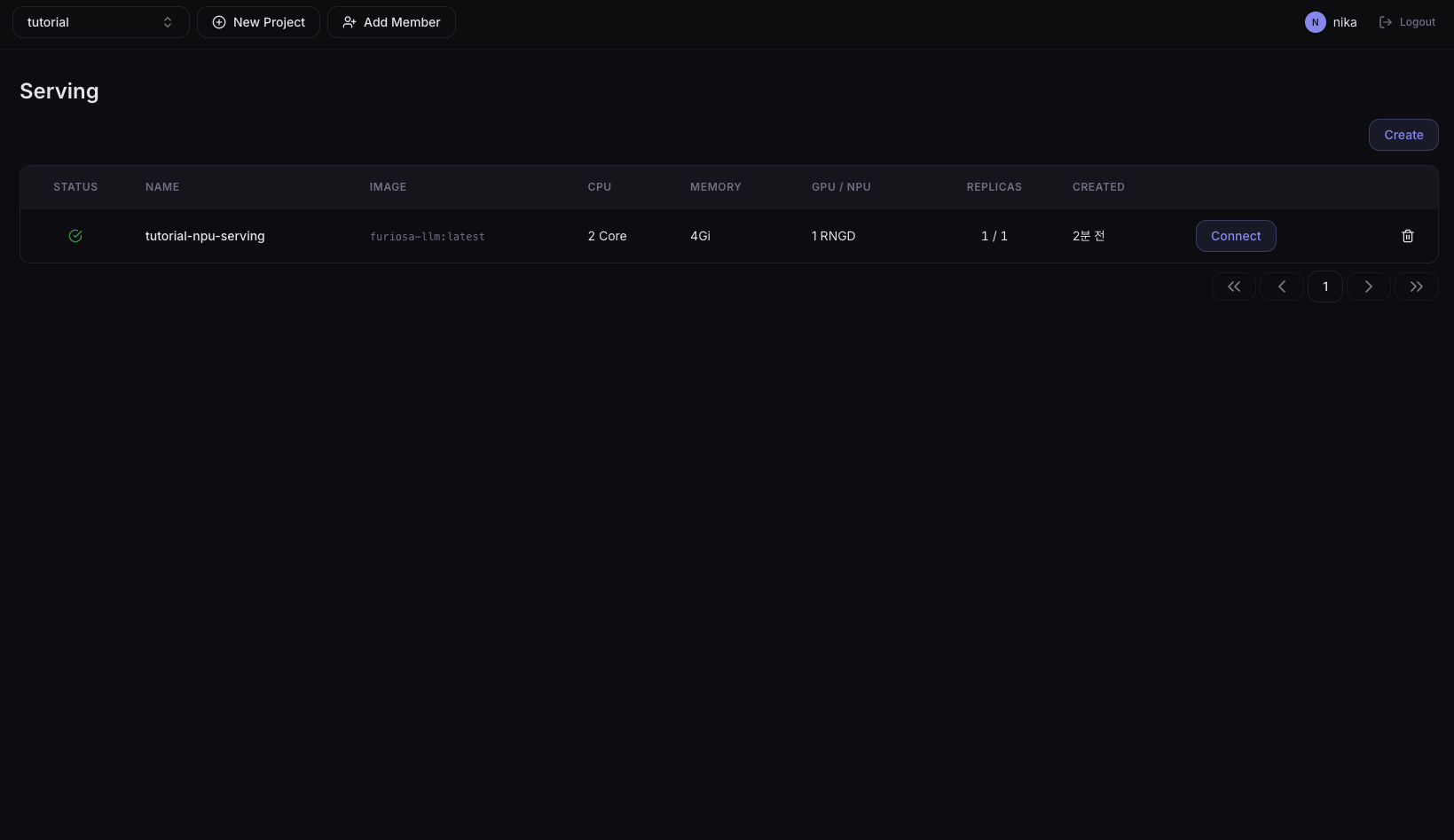
4. Running 상태 확인
좌측 사이드바에서 Development > Serving을 클릭하여 tutorial-npu-serving의 상태가 Running이 되는지 확인합니다.
GPU 서빙 배포
사전 조건
클러스터에 Nvidia GPU 노드가 있어야 합니다. GPU 노드가 없으면 이 단계를 건너뛰세요.
NPU 서빙 배포와 동일하게 진행하되, 3. 배포 설정 입력에서 Artifact를 base(GPU)로 선택합니다.
다음 단계
→ 07. Playground 테스트 — NPU/GPU 응답 품질 및 속도 비교
→ 08. 모니터링 지표 확인 — 실시간 서빙 메트릭 대시보드 확인