모델 품질 평가 (EvaluationRun)
모델별 정확도와 응답 성능을 측정하는 단계로, 모델 간 비교나 NPU 컴파일 후 성능 검증 등의 목적으로 사용합니다.
평가는 Dataset 등록 → Evaluation Method 정의 → 평가 실행의 순서로 진행합니다.
1. Dataset 등록
좌측 사이드바에서 Resources > Datasets 메뉴를 클릭합니다.
우측 상단 + Dataset 만들기 버튼을 눌러 아래 정보를 입력합니다.
| 필드 | 값 |
|---|---|
| Name | tutorial-eval |
| Version | main |
| Description | (선택) |
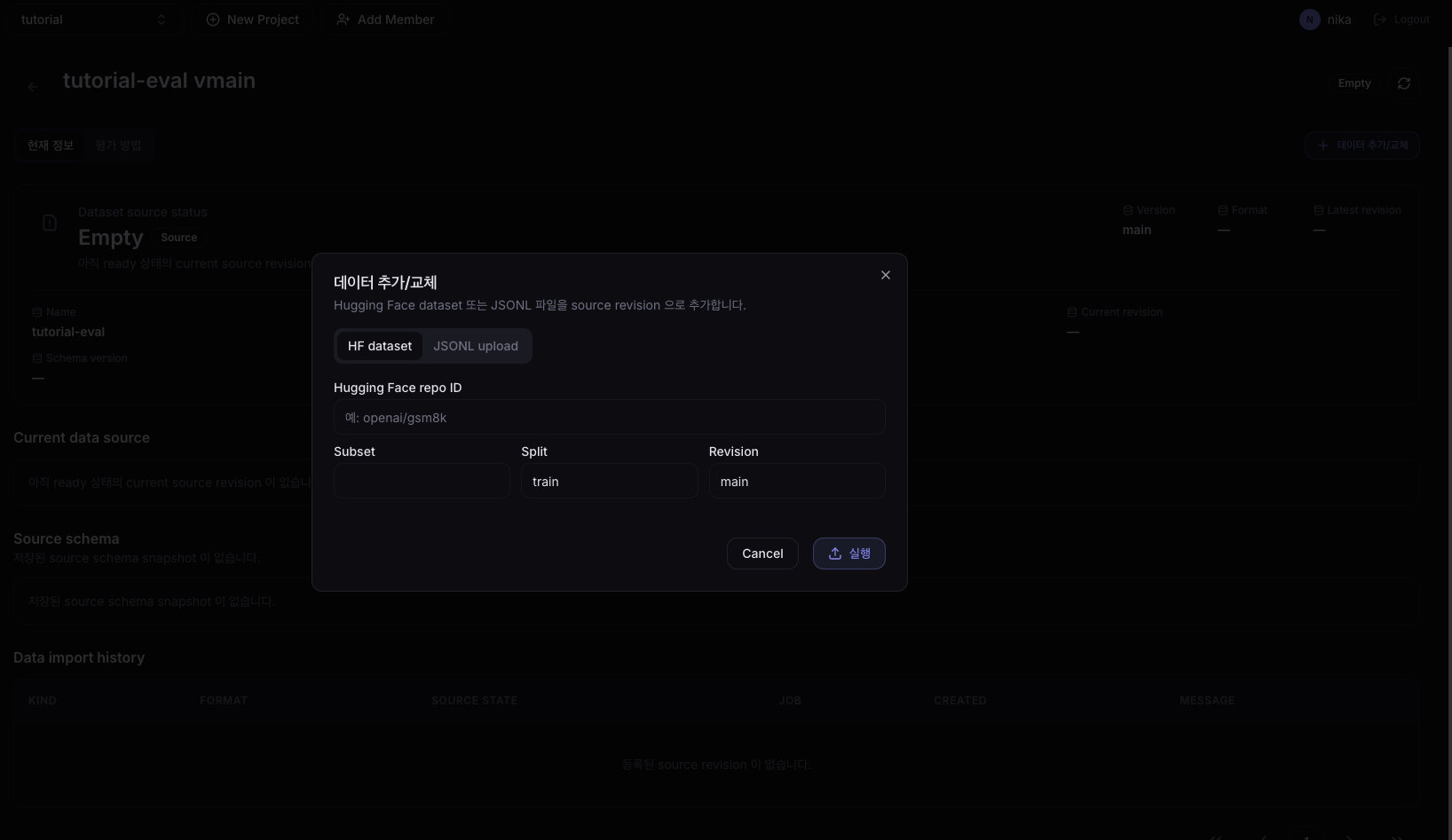
생성된 Dataset을 클릭하여 상세 화면으로 이동한 뒤, 현재 정보 탭 우측 상단의 + 데이터 추가/교체 버튼을 클릭합니다.
데이터 소스 선택
데이터 소스는 HF dataset과 JSONL dataset 두 가지를 지원합니다.
- HF dataset: Hugging Face Hub의 데이터셋을 직접 가져옵니다.
- JSONL dataset: 로컬에서 준비한 JSONL 파일을 업로드합니다.
HF dataset을 사용하는 경우
HF dataset을 선택하고 아래 값을 입력합니다.
| 필드 | 값 |
|---|---|
| Hugging Face repo ID | openai/gsm8k |
| Subset | main |
| Split | train |
| Revision | main |
각 필드는 Hugging Face 데이터셋 페이지에서 확인할 수 있는 값들로, 평가하려는 데이터셋에 맞게 자유롭게 변경할 수 있습니다.
실행 버튼을 클릭하면 데이터셋을 가져옵니다. 작업이 완료되면 상태가 Ready로 바뀝니다.
JSONL dataset을 사용하는 경우
손에 있는 데이터를 그대로 평가에 쓰고 싶다면 JSONL dataset을 선택합니다. 각 줄이 하나의 평가 샘플이 되는 JSON Lines 형식으로 준비하면 됩니다.
{"input": "What is 2+2?", "expected_output": "4"}
{"input": "Capital of France?", "expected_output": "Paris"}
{"input": "Color of the sky?", "expected_output": "Blue"}
input: 모델에 줄 질문/프롬프트expected_output: 정답으로 비교할 기대 출력
별도 Dataset(예: tutorial-eval-jsonl)을 새로 만들고, + 데이터 추가/교체에서 JSONL dataset을 선택해 위 형식의 파일을 업로드합니다. 이후 흐름은 HF dataset과 동일하게 상태가 Ready로 바뀔 때까지 기다립니다.
2. Evaluation Method 만들기
Dataset 상세 화면에서 평가 방법 탭을 클릭한 뒤, + Evaluation Method 만들기 버튼을 누릅니다.
폼은 Dataset의 source schema를 기준으로 만들어지므로, HF dataset이냐 JSONL dataset이냐에 따라 입력해야 하는 필드가 달라집니다. 사용한 Dataset 유형에 맞는 안내를 따라가세요.
HF dataset인 경우
HF dataset(예: openai/gsm8k)으로 진행하고 있다면 아래 화면이 보입니다.
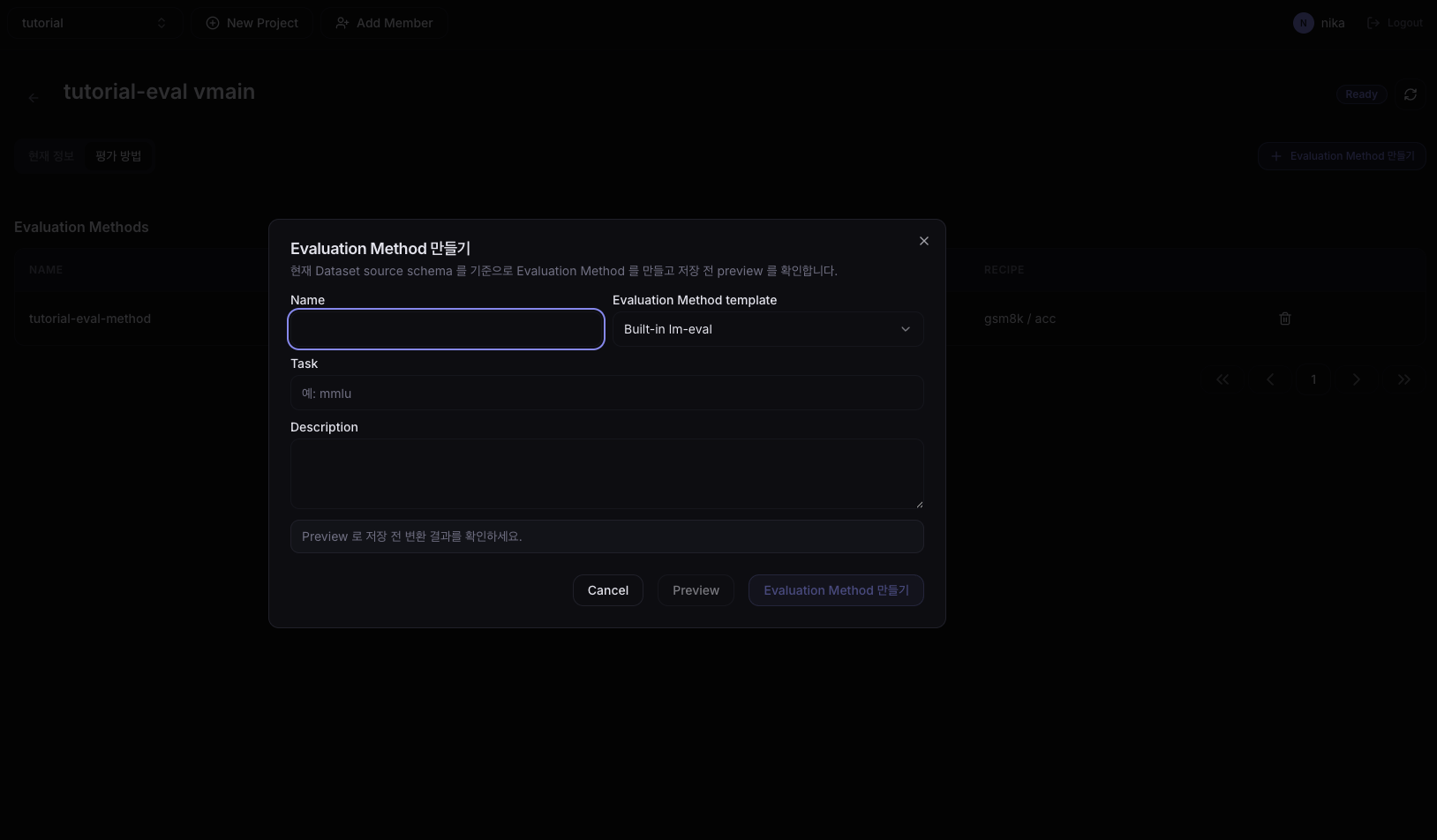
| 필드 | 값 |
|---|---|
| Name | tutorial-eval-method |
| Evaluation Method template | Built-in-lm-eval |
| Task | gsm8k |
| Description | (선택) |
각 필드의 의미는 다음과 같습니다.
- Evaluation Method template: 어떤 평가 방식을 쓸지 정하는 템플릿. HF의 표준 벤치마크는
Built-in-lm-eval을 사용합니다. - Task: lm-eval-harness에서 정의된 태스크 이름. gsm8k를 평가할 거라면
gsm8k로 정확히 입력합니다(오타 시 평가 Job이 실패합니다).
Preview에서 설정을 확인한 뒤 Evaluation Method 만들기를 클릭합니다.
JSONL dataset인 경우
JSONL dataset으로 진행하고 있다면 아래 화면이 보입니다. HF 화면과 달리 JSONL의 어느 키를 입력/정답으로 쓸지 직접 지정하는 필드들이 등장합니다.
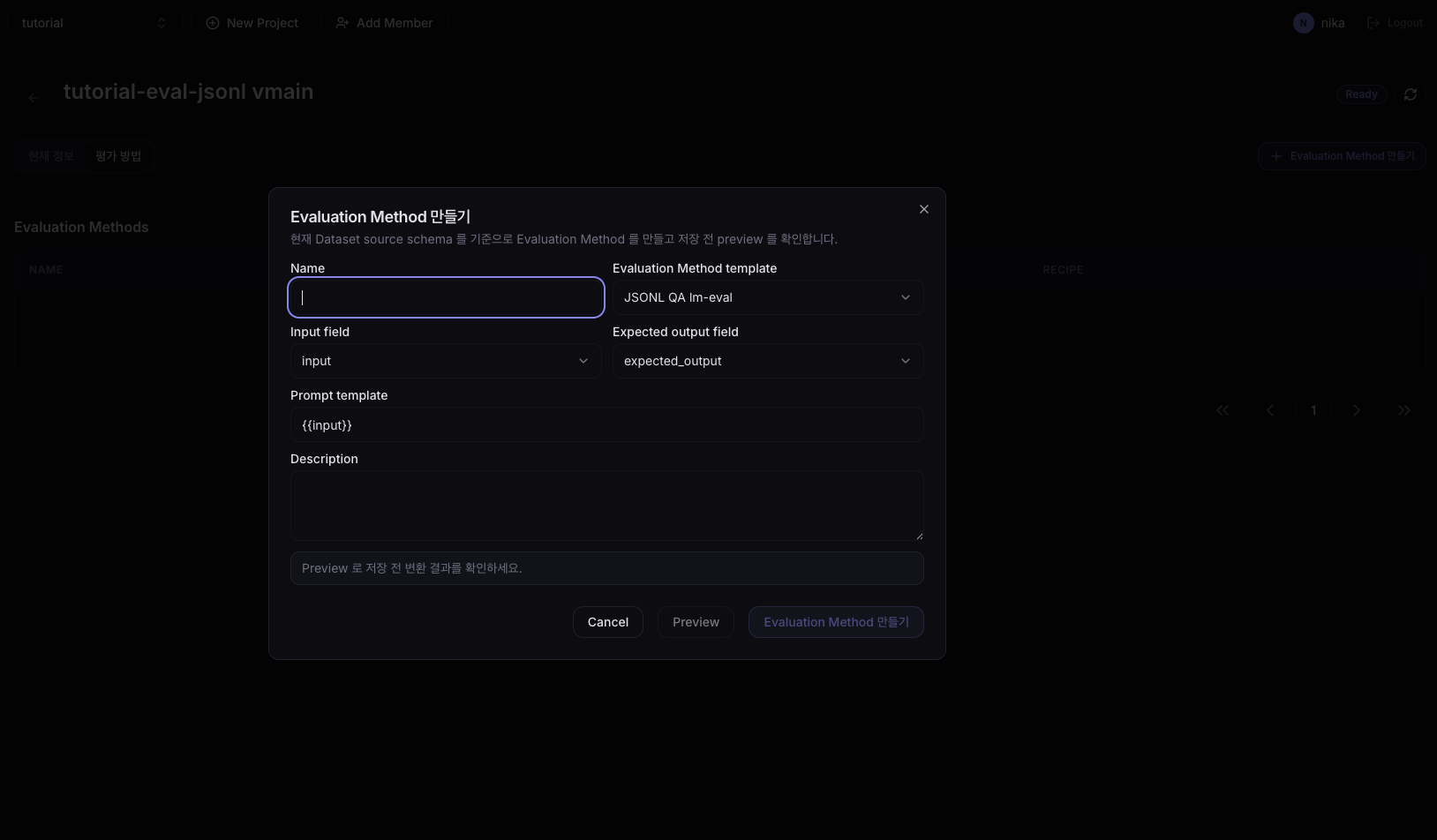
| 필드 | 값 |
|---|---|
| Name | tutorial-eval-jsonl-method |
| Evaluation Method template | JSONL QA lm-eval |
| Input field | input |
| Expected output field | expected_output |
| Prompt template | {{input}} |
| Description | (선택) |
각 필드의 의미는 다음과 같습니다.
- Evaluation Method template: JSONL은 일반적으로
JSONL QA lm-eval을 사용합니다. - Input field / Expected output field: JSONL 각 줄에서 모델 입력과 정답으로 사용할 키 이름. 위 예시 JSONL이면 각각
input,expected_output입니다. - Prompt template: 실제 모델에 들어갈 프롬프트 형태.
{{input}}자리에 JSONL의input값이 치환됩니다. 시스템 지시문이나 추가 컨텍스트를 앞뒤로 붙이고 싶을 때 이 템플릿을 수정합니다.
Preview에서 실제로 채워질 프롬프트와 기대 출력을 확인한 뒤 저장합니다. 이후 평가 실행 흐름은 HF dataset과 동일합니다.
3. 평가 실행
위 화면에서 Eval 버튼을 클릭하면 3단계 마법사가 열립니다.
Step 1. Dataset 선택
평가에 사용할 Dataset을 선택합니다. 사용한 Dataset 유형에 맞춰 앞서 등록한 항목을 고릅니다.
- HF dataset인 경우:
tutorial-eval - JSONL dataset인 경우:
tutorial-eval-jsonl
Step 2. Evaluation Method 선택
어떤 방식으로 평가할지 정의된 Evaluation Method를 선택합니다. Dataset 유형에 맞춰 앞서 만든 Method를 고릅니다.
- HF dataset인 경우:
tutorial-eval-method(Built-in-lm-eval, task=gsm8k) - JSONL dataset인 경우:
tutorial-eval-jsonl-method(JSONL QA lm-eval)
Step 3. 컬럼 매핑 및 실행 옵션
Evaluation Method가 요구하는 입력 컬럼(예: 질문, 정답)이 Dataset의 어떤 컬럼과 연결될지 보여줍니다. gsm8k처럼 표준 스키마를 따르는 데이터셋은 기본값으로도 정상 동작합니다. 사용 중인 Dataset의 컬럼명이 다르거나 일부 필드를 다른 컬럼으로 대체하고 싶을 때만 매핑을 조정합니다.
이어서 평가 실행 옵션을 확인합니다. 각 항목은 다음을 의미합니다.
- Limit (optional): 평가에 사용할 샘플 개수 상한입니다. 비워두면 Dataset 전체를 사용합니다. 빠르게 동작만 확인하고 싶을 때 작은 값(예: 10)으로 지정합니다.
- Batch size: 한 번에 모델에 보낼 입력 묶음 크기입니다. 클수록 처리량이 늘지만 메모리를 더 사용합니다. 기본값
1로 시작합니다. - 동시 요청 수: 서빙 엔드포인트로 동시에 보낼 요청 수입니다. 값을 키우면 평가가 빨라지지만 서빙 리소스 부담이 커집니다. 기본값
1로 시작합니다. - Few-shot 수 (optional): 프롬프트에 함께 넣어줄 예시 개수입니다. gsm8k 같은 추론 태스크는 보통 5~8을 사용하지만, 비워두면 Evaluation Method에 정의된 기본값을 사용합니다.
- Serving CPU / Serving memory / Serving accelerator 수: 평가를 위해 임시로 띄우는 서빙 Pod의 리소스 요청량입니다.
기본값으로 진행해도 되며, 위 설명을 참고해 필요한 값만 조정한 뒤 평가를 실행합니다.
4. 결과 확인
좌측 사이드바의 Evaluations 탭을 클릭하면 실행 중/완료된 평가 목록을 확인할 수 있습니다. 평가가 완료되면 상태가 Succeeded로 바뀌고, 결과를 클릭하면 상세 메트릭을 확인할 수 있습니다.
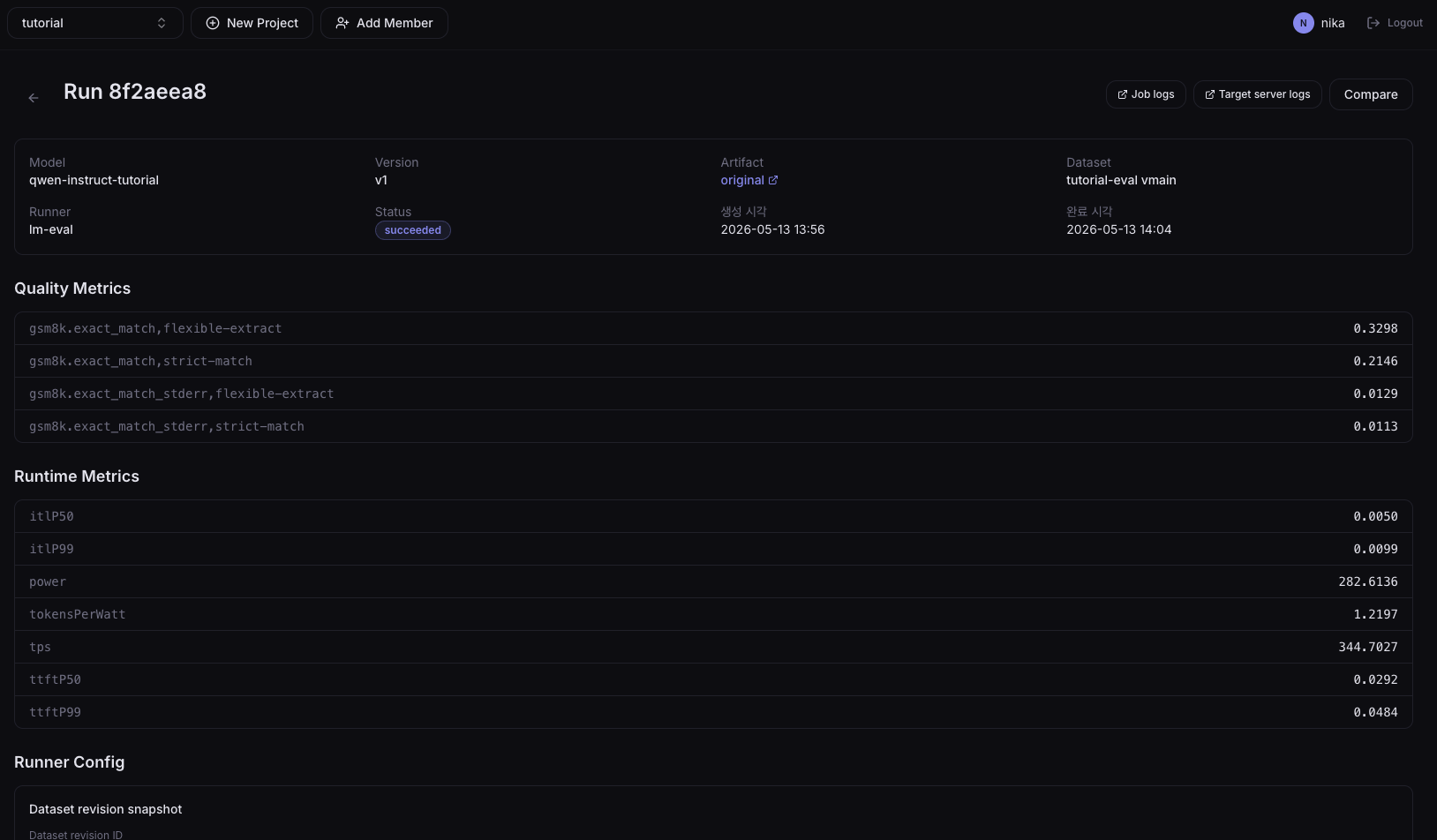
상세 화면의 메트릭은 크게 Quality Metrics(모델 정확도)와 Runtime Metrics(서빙 성능) 두 가지로 나뉩니다.
Quality Metrics
모델이 정답을 얼마나 맞췄는지 보여주는 지표입니다. 메트릭 이름은 <task>.<metric>,<filter> 형식으로, 동일 결과에 대해 추출 방식이 다른 점수가 함께 표시됩니다.
gsm8k.exact_match,strict-match: 모델 출력에서 정답을 엄격하게 추출했을 때의 정답률. 답 형식이 평가 스크립트가 기대하는 패턴과 정확히 일치할 때만 정답으로 인정합니다.gsm8k.exact_match,flexible-extract: 같은 정답률을 좀 더 관대한 추출 규칙으로 계산한 값. 모델이 답을 약간 다른 형식으로 내놓아도 인정해주므로,strict-match보다 점수가 높게 나오는 게 일반적입니다. 두 값 차이가 크다면 모델은 정답을 알지만 출력 형식을 제대로 못 맞추고 있다는 신호입니다.gsm8k.exact_match_stderr,*: 위 정답률의 표준오차(standard error). 샘플 수가 작거나 결과 분산이 크면 값이 커집니다. 두 모델/아티팩트를 비교할 때 차이가 stderr보다 작다면 통계적으로 유의미하지 않을 수 있습니다.
Runtime Metrics
평가 도중 띄운 서빙 Pod에서 측정된 성능 지표입니다.
ttftP50/ttftP99(초): Time To First Token. 요청을 보낸 시점부터 첫 토큰이 돌아올 때까지 걸린 시간의 중앙값(P50)과 99분위(P99). 체감 응답 지연을 좌우합니다.itlP50/itlP99(초): Inter-Token Latency. 첫 토큰 이후 후속 토큰들이 얼마나 빠르게 이어 나오는지를 나타내는 토큰 간 간격의 P50/P99. 스트리밍 응답 속도와 직결됩니다.tps: Tokens Per Second. 초당 생성 토큰 수(throughput). 높을수록 처리량이 좋습니다.power(W): 평가 중 측정된 평균 전력 소비량.tokensPerWatt: 와트당 생성 토큰 수(tps / power에 해당하는 효율 지표). 같은 모델이라도 NPU(rngd) 아티팩트가 GPU 대비 이 값이 높게 나오는 것이 일반적입니다.
5. 결과 비교 (GPU vs NPU)
NPU 컴파일은 양자화·연산 치환 등으로 인해 GPU 대비 정확도가 미세하게 달라질 수 있습니다. 운영 반영 전에 같은 모델의 GPU 아티팩트와 NPU 컴파일 결과를 동일 Dataset으로 평가하고, 두 결과를 직접 비교합니다.
비교 평가 준비
같은 Dataset(tutorial-eval)에 대해 두 번의 평가를 실행합니다. 두 평가 모두 동일한 Evaluation Method를 사용해야 결과를 1:1로 맞출 수 있습니다.
| 평가 | 대상 아티팩트 | Dataset | Evaluation Method |
|---|---|---|---|
| Run A | GPU(base) | tutorial-eval | tutorial-eval-method |
| Run B | NPU(컴파일 결과, 예: rngd) | tutorial-eval | tutorial-eval-method |
Compare 화면
두 평가가 모두 Succeeded 상태가 되면, Evaluations 목록에서 비교할 Run들을 선택하고 Compare 버튼을 클릭합니다.
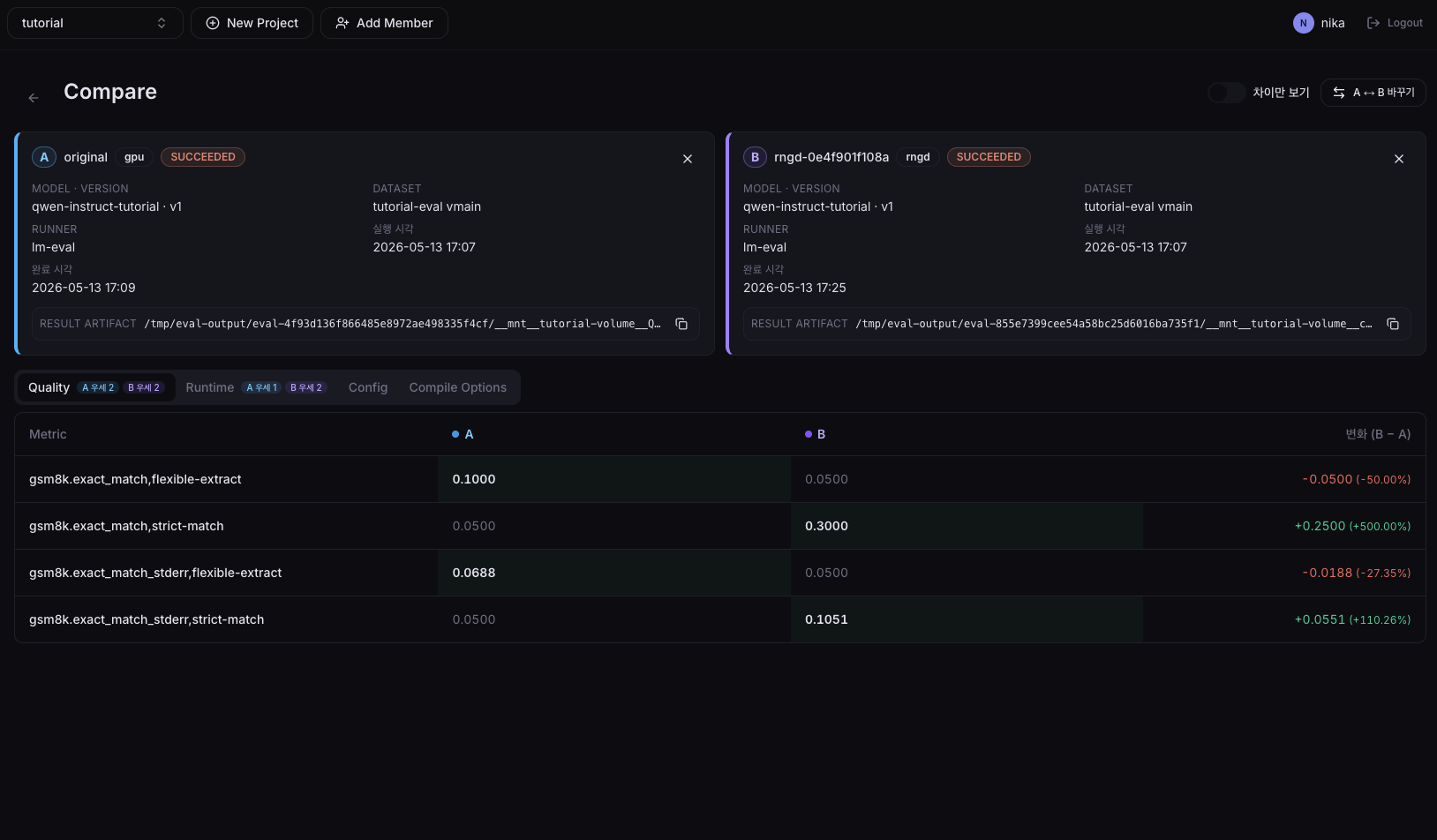
비교 화면에서는 Quality Metrics와 Runtime Metrics가 두 Run을 나란히 보여주며, 다음을 한 눈에 확인할 수 있습니다.
- 정확도 손실:
gsm8k.exact_match,strict-match등 Quality Metrics가 GPU 대비 어느 정도 변했는지. 차이가exact_match_stderr범위 이내라면 통계적으로 동등하다고 볼 수 있습니다. - 속도/효율 이득:
tps,ttft,tokensPerWatt같은 Runtime Metrics에서 NPU가 GPU 대비 얼마나 빠르고 효율적인지.
다음 단계
→ 07. 모델 서빙 배포 — NPU 또는 GPU 서빙 배포